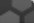We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Most cancer tissues showed weak to moderate nuclear positivity. A few cases of melanomas, adenocarcinoma of lung and hepatocellular carcinomas showed strong staining. Carcinoids, thyroid, kidney stomach, urothelium, testis and skin cancers were weakly stained or negative.
GENE INFORMATION
Gene name
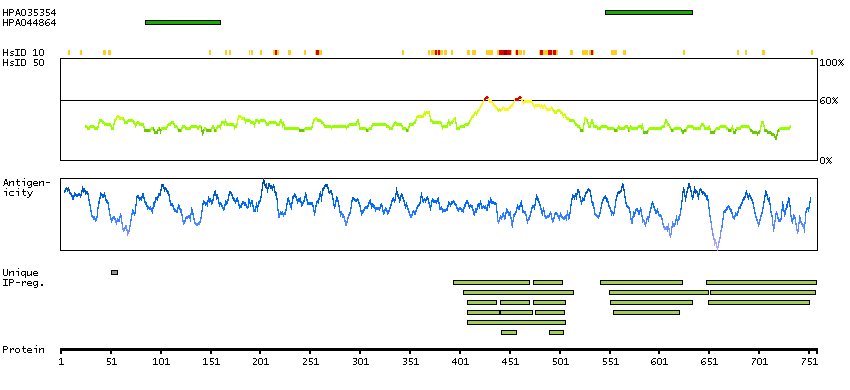
BARD1
Synonyms
Description
BRCA1 associated RING domain 1 (HGNC Symbol)
Entrez gene summary
This gene encodes a protein which interacts with the N-terminal region of BRCA1. In addition to its ability to bind BRCA1 in vivo and in vitro, it shares homology with the 2 most conserved regions of BRCA1: the N-terminal RING motif and the C-terminal BRCT domain. The RING motif is a cysteine-rich sequence found in a variety of proteins that regulate cell growth, including the products of tumor suppressor genes and dominant protooncogenes. This protein also contains 3 tandem ankyrin repeats. The BARD1/BRCA1 interaction is disrupted by tumorigenic amino acid substitutions in BRCA1, implying that the formation of a stable complex between these proteins may be an essential aspect of BRCA1 tumor suppression. This protein may be the target of oncogenic mutations in breast or ovarian cancer. Multiple alternatively spliced transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, Sep 2013]
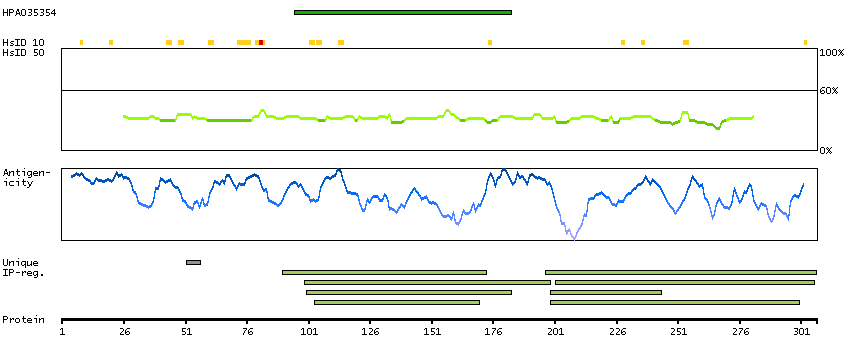
Q99728 [Direct mapping] BRCA1-associated RING domain protein 1
Show all
Predicted intracellular proteins Plasma proteins Cancer-related genes Mutational cancer driver genes Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0000151 [ubiquitin ligase complex] GO:0000724 [double-strand break repair via homologous recombination] GO:0001894 [tissue homeostasis] GO:0003723 [RNA binding] GO:0004842 [ubiquitin-protein transferase activity] GO:0005515 [protein binding] GO:0005634 [nucleus] GO:0005654 [nucleoplasm] GO:0005730 [nucleolus] GO:0005737 [cytoplasm] GO:0006281 [DNA repair] GO:0006302 [double-strand break repair] GO:0006303 [double-strand break repair via nonhomologous end joining] GO:0006974 [cellular response to DNA damage stimulus] GO:0007050 [cell cycle arrest] GO:0008270 [zinc ion binding] GO:0016567 [protein ubiquitination] GO:0016874 [ligase activity] GO:0019900 [kinase binding] GO:0031436 [BRCA1-BARD1 complex] GO:0031441 [negative regulation of mRNA 3'-end processing] GO:0042325 [regulation of phosphorylation] GO:0042803 [protein homodimerization activity] GO:0043065 [positive regulation of apoptotic process] GO:0043066 [negative regulation of apoptotic process] GO:0043231 [intracellular membrane-bounded organelle] GO:0045003 [double-strand break repair via synthesis-dependent strand annealing] GO:0045732 [positive regulation of protein catabolic process] GO:0046826 [negative regulation of protein export from nucleus] GO:0046982 [protein heterodimerization activity] GO:0070531 [BRCA1-A complex] GO:0085020 [protein K6-linked ubiquitination]
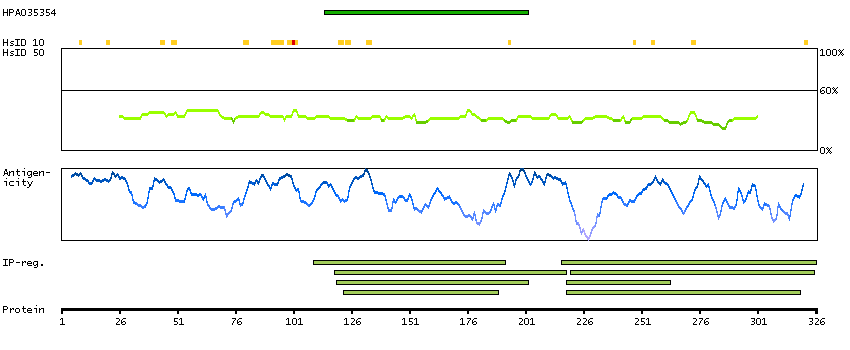
A0A087X2H0 [Direct mapping] BRCA1-associated RING domain protein 1
Show all
SPOCTOPUS predicted membrane proteins Predicted intracellular proteins Cancer-related genes Mutational cancer driver genes Protein evidence (Ezkurdia et al 2014)