We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
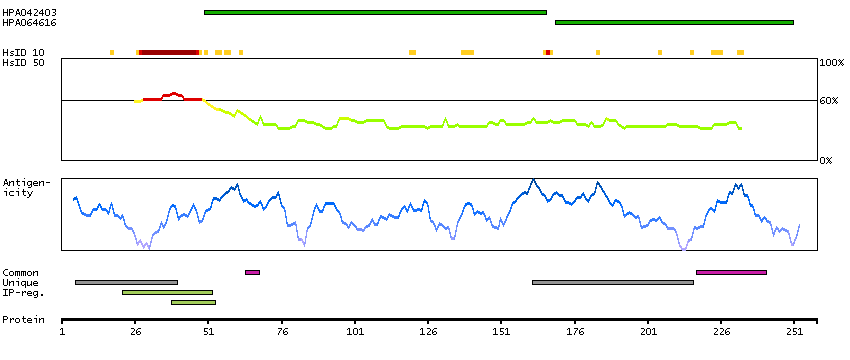
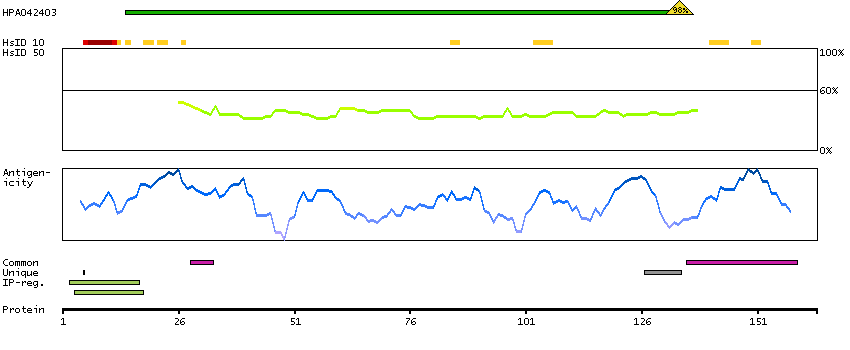
The protein encoded by this gene binds proteins of the TEA domain family of transcription factors (TEFs) through the Vg (vestigial) homology region found in its N-terminus. It may thus function as a specific coactivator for the mammalian TEFs. [provided by RefSeq, Sep 2009]