We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Secreted protein, tissue location of RNA and protein might differ and correlation is complex. Antibody staining in cells/structures not annotated, view images.
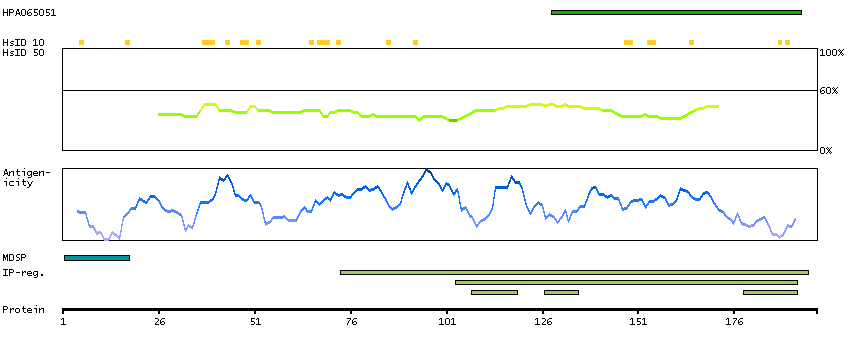
The protein encoded by this gene is a T cell-derived cytokine that shares the sequence similarity with IL17. This cytokine was reported to stimulate the release of tumor necrosis factor alpha and interleukin 1 beta from a monocytic cell line. The expression of this cytokine was found to be restricted to activated T cells. [provided by RefSeq, Jul 2008]