We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
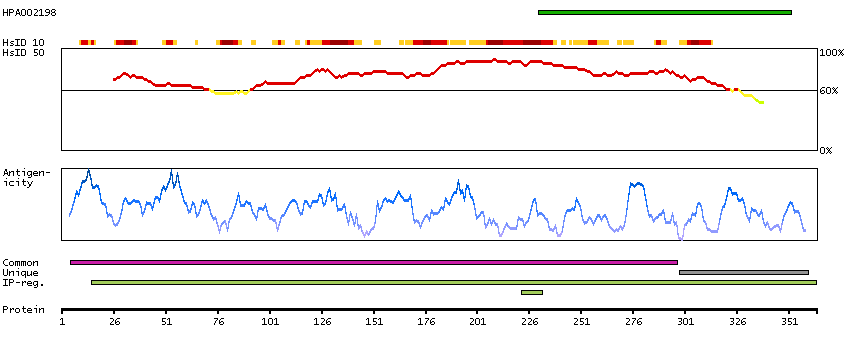
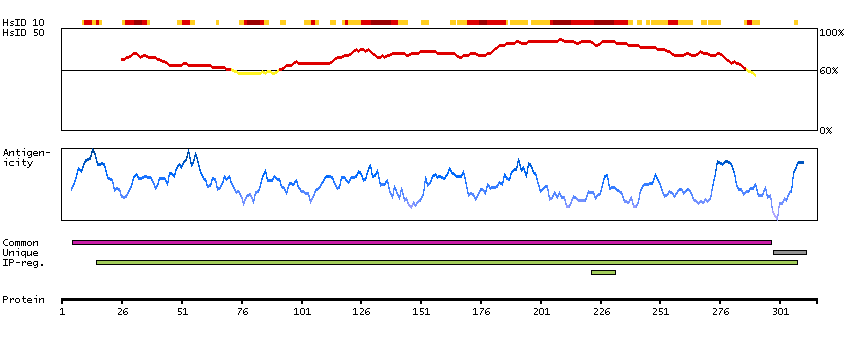
Fructose-1,6-bisphosphate aldolase (EC 4.1.2.13) is a tetrameric glycolytic enzyme that catalyzes the reversible conversion of fructose-1,6-bisphosphate to glyceraldehyde 3-phosphate and dihydroxyacetone phosphate. Vertebrates have 3 aldolase isozymes which are distinguished by their electrophoretic and catalytic properties. Differences indicate that aldolases A, B, and C are distinct proteins, the products of a family of related 'housekeeping' genes exhibiting developmentally regulated expression of the different isozymes. The developing embryo produces aldolase A, which is produced in even greater amounts in adult muscle where it can be as much as 5% of total cellular protein. In adult liver, kidney and intestine, aldolase A expression is repressed and aldolase B is produced. In brain and other nervous tissue, aldolase A and C are expressed about equally. There is a high degree of homology between aldolase A and C. Defects in ALDOB cause hereditary fructose intolerance. [provided by RefSeq, Dec 2008]
Enzymes ENZYME proteins Lyases Predicted intracellular proteins Plasma proteins Cancer-related genes Candidate cancer biomarkers Disease related genes Potential drug targets Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0001889 [liver development] GO:0004332 [fructose-bisphosphate aldolase activity] GO:0005515 [protein binding] GO:0005634 [nucleus] GO:0005737 [cytoplasm] GO:0005764 [lysosome] GO:0005815 [microtubule organizing center] GO:0005829 [cytosol] GO:0005886 [plasma membrane] GO:0005975 [carbohydrate metabolic process] GO:0006000 [fructose metabolic process] GO:0006006 [glucose metabolic process] GO:0006094 [gluconeogenesis] GO:0006096 [glycolytic process] GO:0006116 [NADH oxidation] GO:0008092 [cytoskeletal protein binding] GO:0009743 [response to carbohydrate] GO:0009750 [response to fructose] GO:0010043 [response to zinc ion] GO:0014070 [response to organic cyclic compound] GO:0030388 [fructose 1,6-bisphosphate metabolic process] GO:0030867 [rough endoplasmic reticulum membrane] GO:0030868 [smooth endoplasmic reticulum membrane] GO:0031210 [phosphatidylcholine binding] GO:0031668 [cellular response to extracellular stimulus] GO:0032781 [positive regulation of ATPase activity] GO:0032869 [cellular response to insulin stimulus] GO:0034451 [centriolar satellite] GO:0042493 [response to drug] GO:0042594 [response to starvation] GO:0042802 [identical protein binding] GO:0043200 [response to amino acid] GO:0043231 [intracellular membrane-bounded organelle] GO:0043434 [response to peptide hormone] GO:0044281 [small molecule metabolic process] GO:0046688 [response to copper ion] GO:0048471 [perinuclear region of cytoplasm] GO:0051117 [ATPase binding] GO:0051384 [response to glucocorticoid] GO:0051591 [response to cAMP] GO:0061609 [fructose-1-phosphate aldolase activity] GO:0061621 [canonical glycolysis] GO:0061624 [fructose catabolic process to hydroxyacetone phosphate and glyceraldehyde-3-phosphate] GO:0070061 [fructose binding] GO:0070062 [extracellular exosome] GO:0070072 [vacuolar proton-transporting V-type ATPase complex assembly] GO:0070741 [response to interleukin-6]