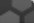We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
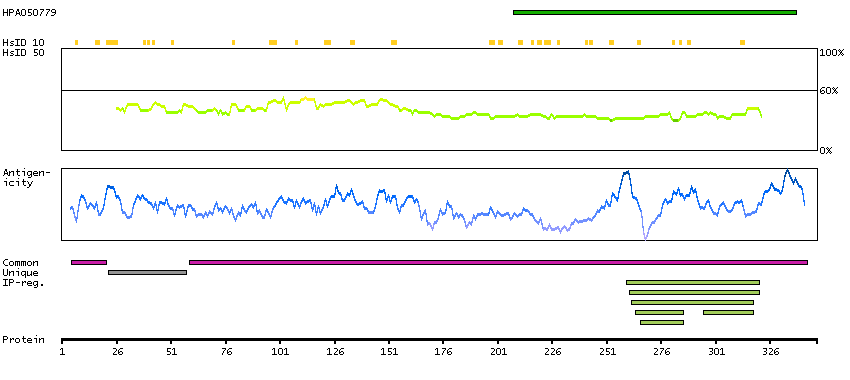
Most cancers showed moderate nuclear positivity. Few ovarian cancers along with rare colorectal, cervical, urothelial, head and neck cancers showed strong positivity.
Most malignant lymphomas and breast cancers along with several malignant gliomas and endometrial cancers as well as a few ovarian, cervical and lung cancers showed moderate to strong nuclear positivity. Remaining malignant cells were weakly stained.
GENE INFORMATION
Gene name
NFYA (HGNC Symbol)
Synonyms
CBF-B, HAP2, NF-YA
Description
Nuclear transcription factor Y, alpha (HGNC Symbol)
Entrez gene summary
The protein encoded by this gene is one subunit of a trimeric complex, forming a highly conserved transcription factor that binds to CCAAT motifs in the promoter regions in a variety of genes. Subunit A associates with a tight dimer composed of the B and C subunits, resulting in a trimer that binds to DNA with high specificity and affinity. The sequence specific interactions of the complex are made by the A subunit, suggesting a role as the regulatory subunit. In addition, there is evidence of post-transcriptional regulation in this gene product, either by protein degradation or control of translation. Further regulation is represented by alternative splicing in the glutamine-rich activation domain, with clear tissue-specific preferences for the two isoforms. [provided by RefSeq, Jul 2008]
P23511 [Direct mapping] Nuclear transcription factor Y subunit alpha
Show all
Predicted intracellular proteins Transcription factors Other all-alpha-helical DNA-binding domains Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0001046 [core promoter sequence-specific DNA binding] GO:0001221 [transcription cofactor binding] GO:0003677 [DNA binding] GO:0003700 [transcription factor activity, sequence-specific DNA binding] GO:0005515 [protein binding] GO:0005634 [nucleus] GO:0005654 [nucleoplasm] GO:0006355 [regulation of transcription, DNA-templated] GO:0006366 [transcription from RNA polymerase II promoter] GO:0008134 [transcription factor binding] GO:0016602 [CCAAT-binding factor complex] GO:0032993 [protein-DNA complex] GO:0044212 [transcription regulatory region DNA binding] GO:0044281 [small molecule metabolic process] GO:0045893 [positive regulation of transcription, DNA-templated] GO:0045944 [positive regulation of transcription from RNA polymerase II promoter] GO:0048511 [rhythmic process] GO:2000036 [regulation of stem cell population maintenance] GO:2000648 [positive regulation of stem cell proliferation]
Predicted intracellular proteins Transcription factors Other all-alpha-helical DNA-binding domains Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0001046 [core promoter sequence-specific DNA binding] GO:0003677 [DNA binding] GO:0003700 [transcription factor activity, sequence-specific DNA binding] GO:0005515 [protein binding] GO:0005634 [nucleus] GO:0005654 [nucleoplasm] GO:0006355 [regulation of transcription, DNA-templated] GO:0006366 [transcription from RNA polymerase II promoter] GO:0016602 [CCAAT-binding factor complex] GO:0032993 [protein-DNA complex] GO:0044212 [transcription regulatory region DNA binding] GO:0044281 [small molecule metabolic process] GO:0045893 [positive regulation of transcription, DNA-templated] GO:0048511 [rhythmic process]