We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
This gene encodes a member of the TATA box-binding protein family. TATA box-binding proteins play a critical role in transcription by RNA polymerase II as components of the transcription factor IID (TFIID) complex. The encoded protein does not bind to the TATA box and initiates transcription from TATA-less promoters. This gene plays a critical role in spermatogenesis, and single nucleotide polymorphisms in this gene may be associated with male infertility. Alternatively spliced transcript variants have been observed for this gene, and a pseudogene of this gene is located on the long arm of chromosome 3. [provided by RefSeq, Nov 2011]
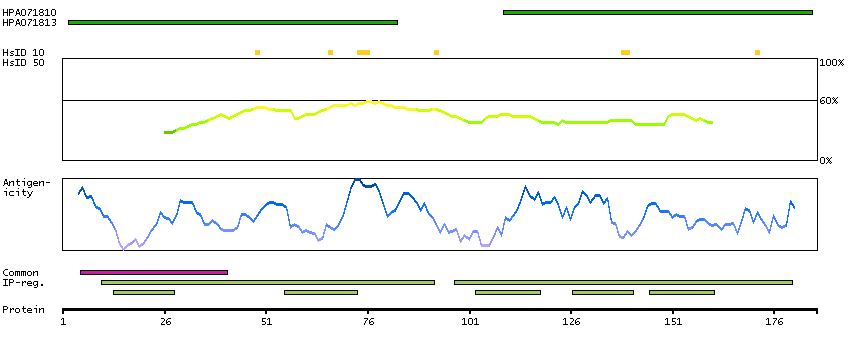
P62380 [Direct mapping] TATA box-binding protein-like protein 1
Show all
Predicted intracellular proteins Transcription factors beta-Sheet binding to DNA Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
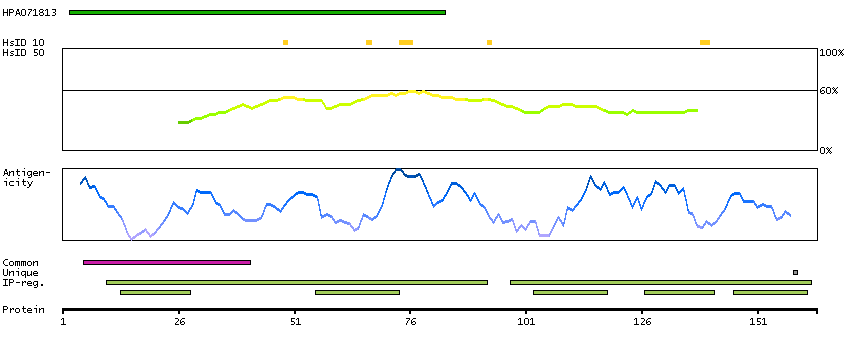
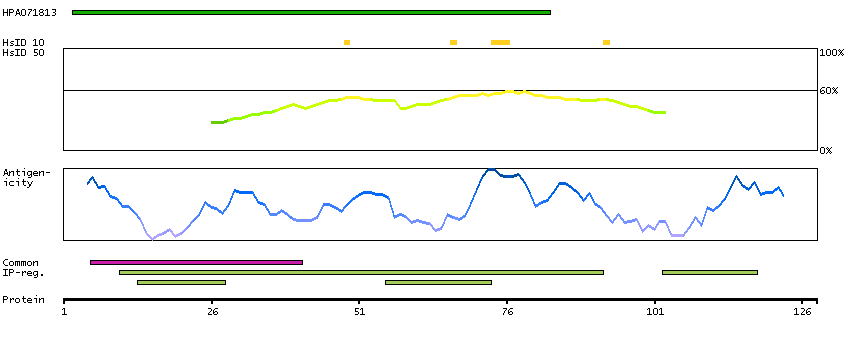
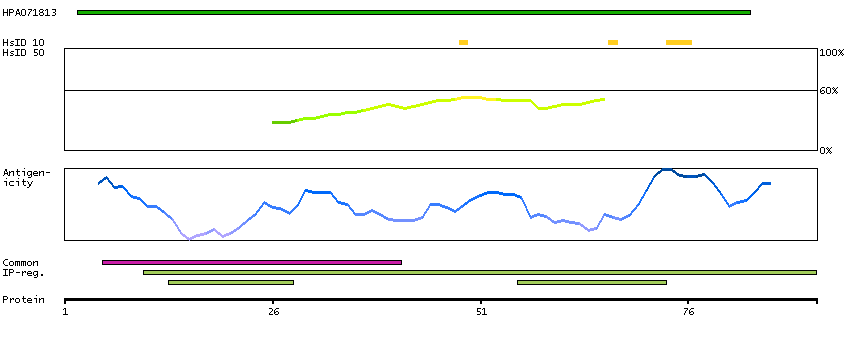
P62380 [Direct mapping] TATA box-binding protein-like protein 1
Show all
Predicted intracellular proteins Transcription factors beta-Sheet binding to DNA Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0003677 [DNA binding] GO:0003713 [transcription coactivator activity] GO:0005515 [protein binding] GO:0005737 [cytoplasm] GO:0006352 [DNA-templated transcription, initiation] GO:0006355 [regulation of transcription, DNA-templated] GO:0006366 [transcription from RNA polymerase II promoter]