We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
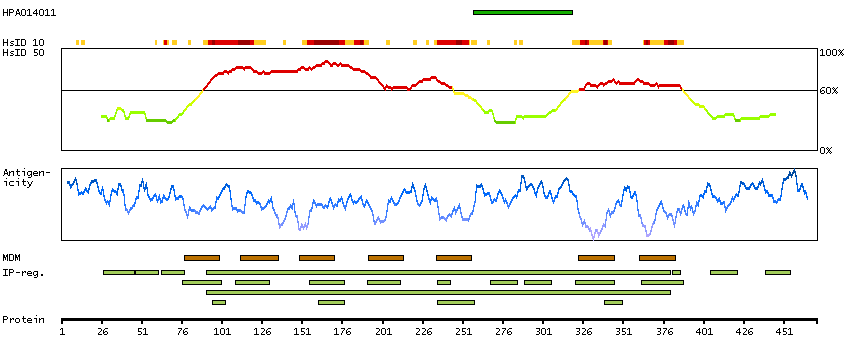
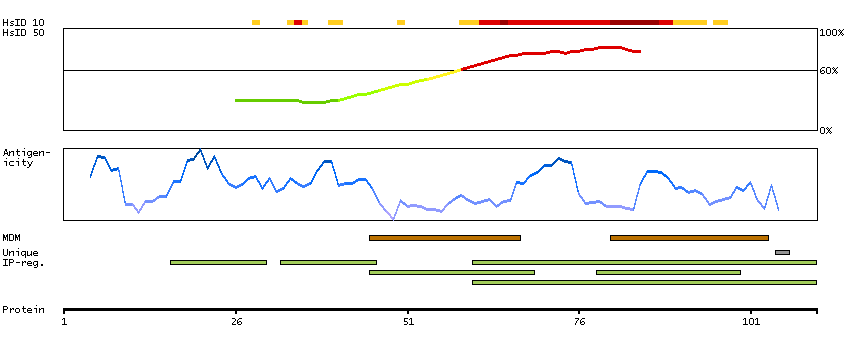
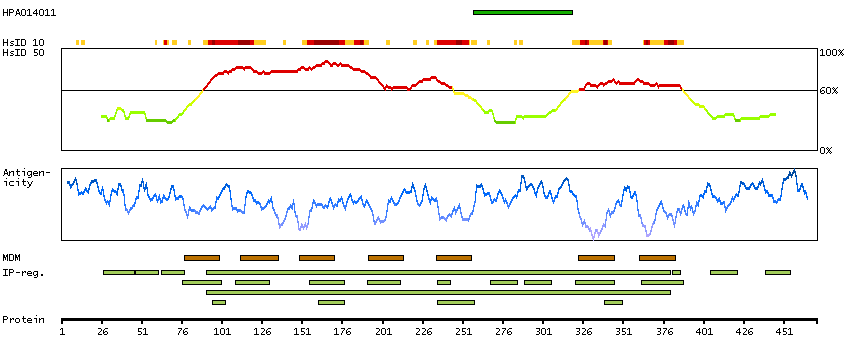
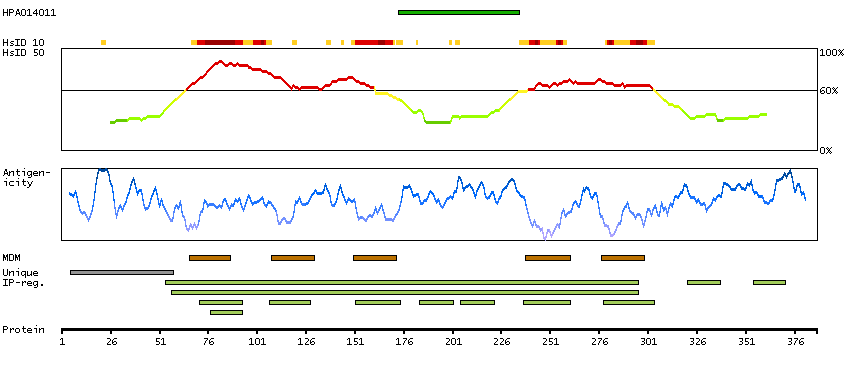
RNA tissue category: Group enriched (brain, caudate, hippocampus, retina)
GENE INFORMATION
Gene name
HTR2A (HGNC Symbol)
Synonyms
5-HT2A, HTR2
Description
5-hydroxytryptamine (serotonin) receptor 2A, G protein-coupled (HGNC Symbol)
Entrez gene summary
This gene encodes one of the receptors for serotonin, a neurotransmitter with many roles. Mutations in this gene are associated with susceptibility to schizophrenia and obsessive-compulsive disorder, and are also associated with response to the antidepressant citalopram in patients with major depressive disorder (MDD). MDD patients who also have a mutation in intron 2 of this gene show a significantly reduced response to citalopram as this antidepressant downregulates expression of this gene. Multiple transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, Sep 2009]