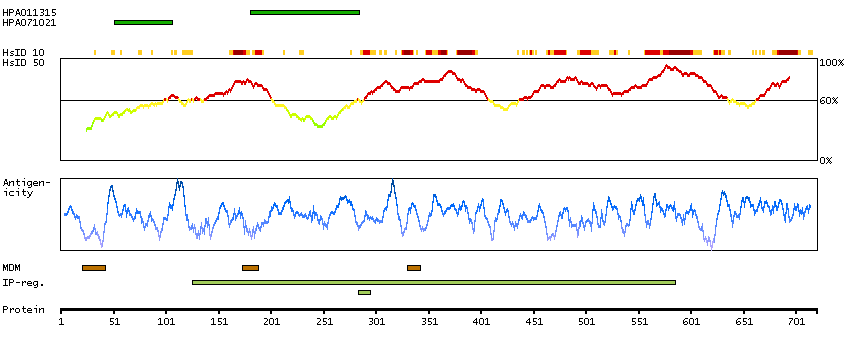
We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Acyl-CoA synthetase long-chain family member 3 (HGNC Symbol)
Entrez gene summary
The protein encoded by this gene is an isozyme of the long-chain fatty-acid-coenzyme A ligase family. Although differing in substrate specificity, subcellular localization, and tissue distribution, all isozymes of this family convert free long-chain fatty acids into fatty acyl-CoA esters, and thereby play a key role in lipid biosynthesis and fatty acid degradation. This isozyme is highly expressed in brain, and preferentially utilizes myristate, arachidonate, and eicosapentaenoate as substrates. The amino acid sequence of this isozyme is 92% identical to that of rat homolog. Two transcript variants encoding the same protein have been found for this gene. [provided by RefSeq, Jul 2008]