We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
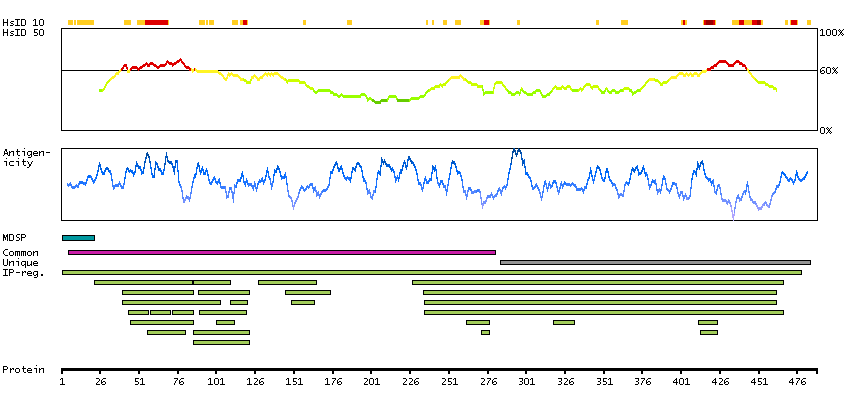
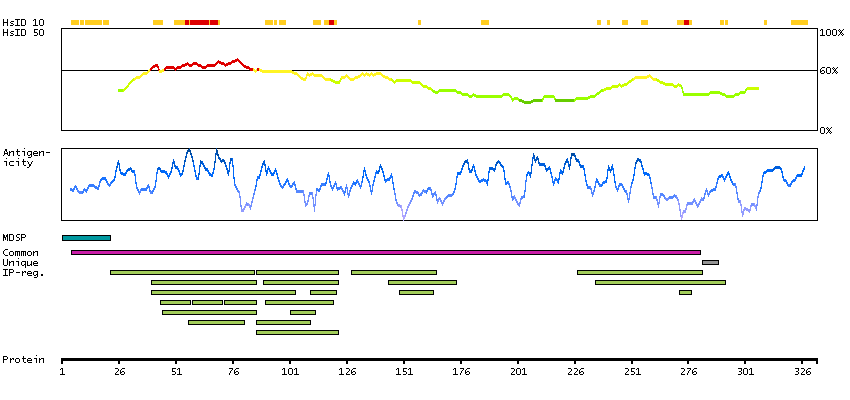
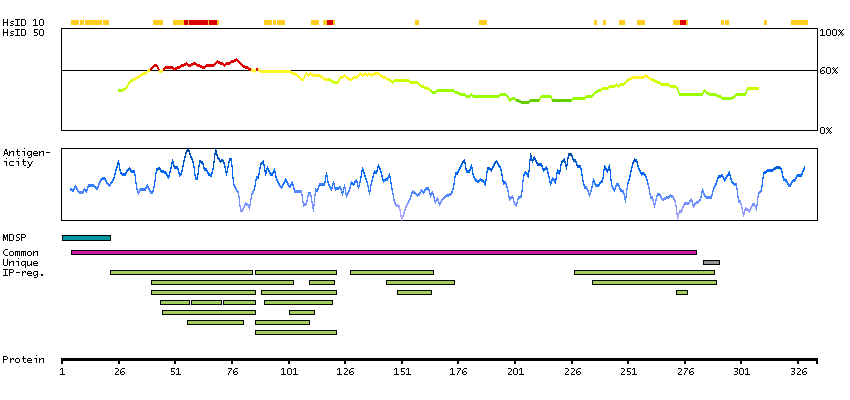
This gene encodes the vitamin K-dependent coagulation factor X of the blood coagulation cascade. This factor undergoes multiple processing steps before its preproprotein is converted to a mature two-chain form by the excision of the tripeptide RKR. Two chains of the factor are held together by 1 or more disulfide bonds; the light chain contains 2 EGF-like domains, while the heavy chain contains the catalytic domain which is structurally homologous to those of the other hemostatic serine proteases. The mature factor is activated by the cleavage of the activation peptide by factor IXa (in the intrisic pathway), or by factor VIIa (in the extrinsic pathway). The activated factor then converts prothrombin to thrombin in the presence of factor Va, Ca+2, and phospholipid during blood clotting. Mutations of this gene result in factor X deficiency, a hemorrhagic condition of variable severity. Alternative splicing results in multiple transcript variants encoding different isoforms that may undergo similar proteolytic processing to generate mature polypeptides. [provided by RefSeq, Aug 2015]