We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
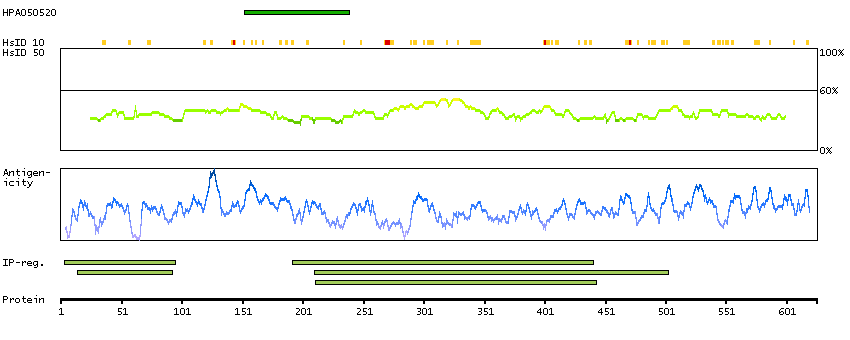
IRAK2 encodes the interleukin-1 receptor-associated kinase 2, one of two putative serine/threonine kinases that become associated with the interleukin-1 receptor (IL1R) upon stimulation. IRAK2 is reported to participate in the IL1-induced upregulation of NF-kappaB. [provided by RefSeq, Jul 2008]