We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Proline-rich protein HaeIII subfamily 2 (HGNC Symbol)
Entrez gene summary
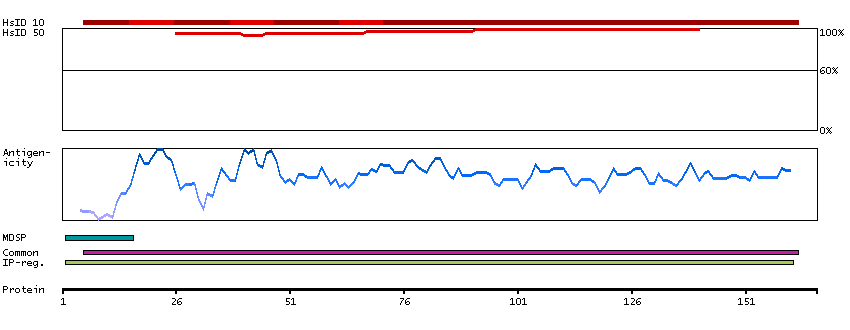
This gene encodes a member of the heterogeneous family of proline-rich salivary glycoproteins. The encoded preproprotein undergoes proteolytic processing to generate one or more mature isoforms before secretion from the parotid and submandibular/sublingual glands. In western population this locus is commonly biallelic and encodes proline-rich protein (PRP) isoforms, PRP-1 and PRP-2. The reference genome encodes the PRP-1 allele. Certain alleles of this gene are associated with susceptibility to dental caries. This gene is located in a cluster of closely related salivary proline-rich proteins on chromosome 12. [provided by RefSeq, Oct 2015]