We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
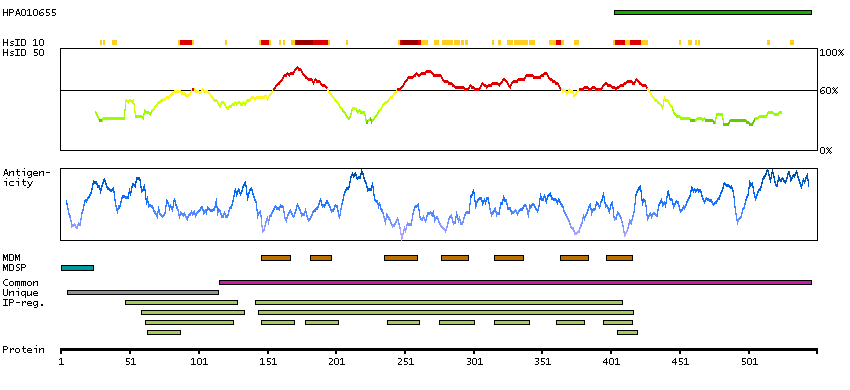
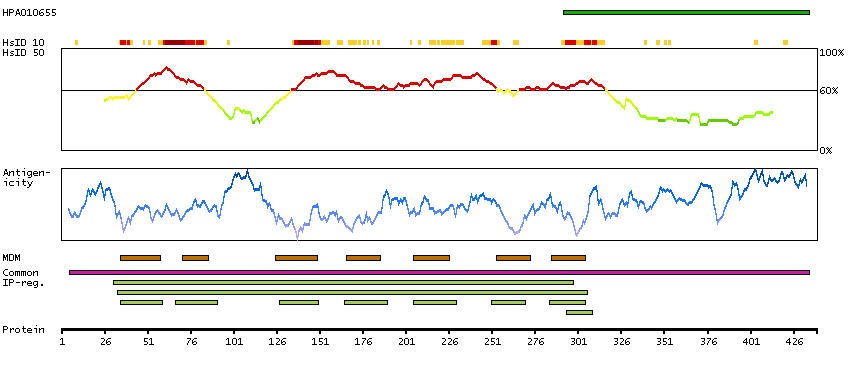
The protein encoded by this gene is a member of the G-protein coupled receptor 2 family. This protein is a receptor for parathyroid hormone (PTH). This receptor is more selective in ligand recognition and has a more specific tissue distribution compared to parathyroid hormone receptor 1 (PTHR1). It is activated only by PTH and not by parathyroid hormone-like hormone (PTHLH) and is particularly abundant in brain and pancreas. Alternative splicing results in multiple transcript variants. [provided by RefSeq, Jan 2013]