We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
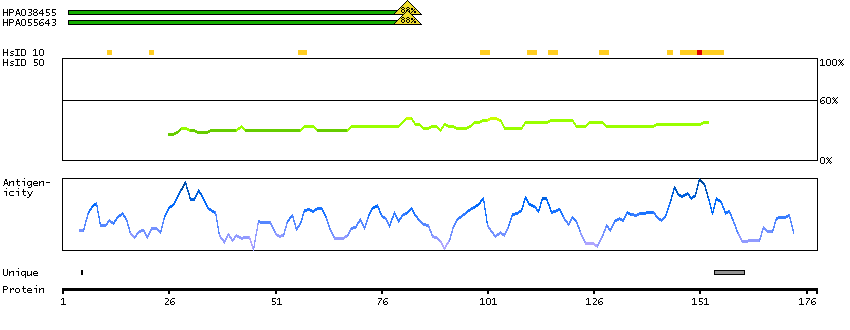
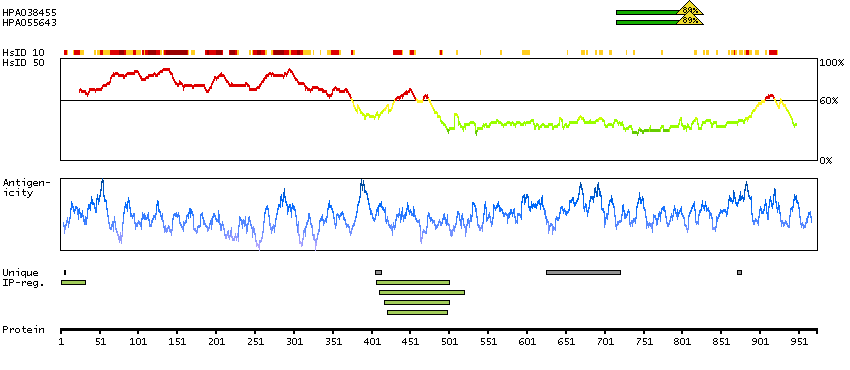
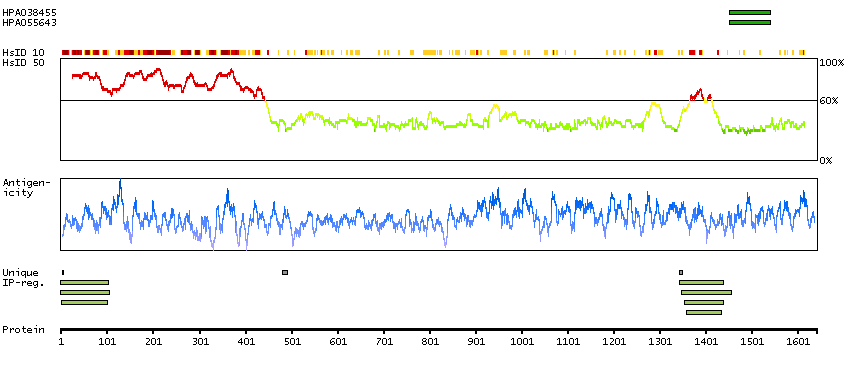
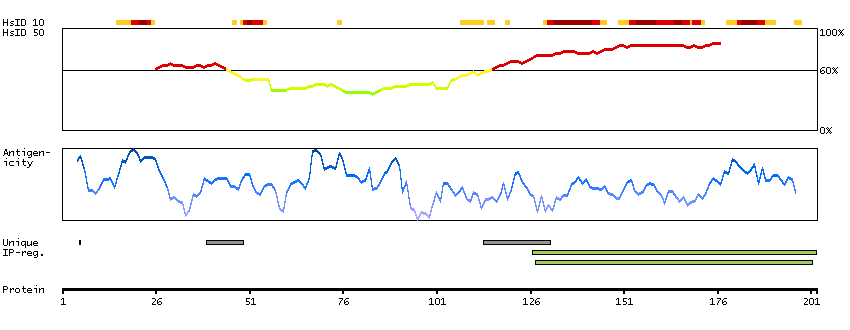
Ankyrin 3, node of Ranvier (ankyrin G) (HGNC Symbol)
Entrez gene summary
Ankyrins are a family of proteins that are believed to link the integral membrane proteins to the underlying spectrin-actin cytoskeleton and play key roles in activities such as cell motility, activation, proliferation, contact, and the maintenance of specialized membrane domains. Multiple isoforms of ankyrin with different affinities for various target proteins are expressed in a tissue-specific, developmentally regulated manner. Most ankyrins are typically composed of three structural domains: an amino-terminal domain containing multiple ankyrin repeats; a central region with a highly conserved spectrin binding domain; and a carboxy-terminal regulatory domain which is the least conserved and subject to variation. Ankyrin 3 is an immunologically distinct gene product from ankyrins 1 and 2, and was originally found at the axonal initial segment and nodes of Ranvier of neurons in the central and peripheral nervous systems. Multiple transcript variants encoding different isoforms have been found for this gene.[provided by RefSeq, Feb 2011]
Predicted intracellular proteins Plasma proteins Cancer-related genes Mutated cancer genes Disease related genes Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0000281 [mitotic cytokinesis] GO:0005200 [structural constituent of cytoskeleton] GO:0005515 [protein binding] GO:0005764 [lysosome] GO:0005783 [endoplasmic reticulum] GO:0005794 [Golgi apparatus] GO:0005886 [plasma membrane] GO:0005923 [bicellular tight junction] GO:0007009 [plasma membrane organization] GO:0007016 [cytoskeletal anchoring at plasma membrane] GO:0007165 [signal transduction] GO:0007409 [axonogenesis] GO:0007411 [axon guidance] GO:0008092 [cytoskeletal protein binding] GO:0009925 [basal plasma membrane] GO:0009986 [cell surface] GO:0010628 [positive regulation of gene expression] GO:0010765 [positive regulation of sodium ion transport] GO:0010960 [magnesium ion homeostasis] GO:0014704 [intercalated disc] GO:0014731 [spectrin-associated cytoskeleton] GO:0016020 [membrane] GO:0016323 [basolateral plasma membrane] GO:0016328 [lateral plasma membrane] GO:0019228 [neuronal action potential] GO:0030315 [T-tubule] GO:0030424 [axon] GO:0030507 [spectrin binding] GO:0030674 [protein binding, bridging] GO:0033268 [node of Ranvier] GO:0033270 [paranode region of axon] GO:0042383 [sarcolemma] GO:0043001 [Golgi to plasma membrane protein transport] GO:0043034 [costamere] GO:0043194 [axon initial segment] GO:0043266 [regulation of potassium ion transport] GO:0044325 [ion channel binding] GO:0045184 [establishment of protein localization] GO:0045202 [synapse] GO:0045211 [postsynaptic membrane] GO:0045296 [cadherin binding] GO:0045838 [positive regulation of membrane potential] GO:0050808 [synapse organization] GO:0071286 [cellular response to magnesium ion] GO:0071709 [membrane assembly] GO:0072659 [protein localization to plasma membrane] GO:0072660 [maintenance of protein location in plasma membrane] GO:0072661 [protein targeting to plasma membrane] GO:1900827 [positive regulation of membrane depolarization during cardiac muscle cell action potential] GO:1902260 [negative regulation of delayed rectifier potassium channel activity] GO:2000651 [positive regulation of sodium ion transmembrane transporter activity]
Predicted intracellular proteins Plasma proteins Cancer-related genes Mutated cancer genes Disease related genes Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0000281 [mitotic cytokinesis] GO:0005200 [structural constituent of cytoskeleton] GO:0005515 [protein binding] GO:0005764 [lysosome] GO:0005783 [endoplasmic reticulum] GO:0005794 [Golgi apparatus] GO:0005886 [plasma membrane] GO:0005923 [bicellular tight junction] GO:0007009 [plasma membrane organization] GO:0007016 [cytoskeletal anchoring at plasma membrane] GO:0007165 [signal transduction] GO:0007409 [axonogenesis] GO:0008092 [cytoskeletal protein binding] GO:0009925 [basal plasma membrane] GO:0009986 [cell surface] GO:0010628 [positive regulation of gene expression] GO:0010765 [positive regulation of sodium ion transport] GO:0010960 [magnesium ion homeostasis] GO:0014704 [intercalated disc] GO:0014731 [spectrin-associated cytoskeleton] GO:0016323 [basolateral plasma membrane] GO:0016328 [lateral plasma membrane] GO:0019228 [neuronal action potential] GO:0030315 [T-tubule] GO:0030507 [spectrin binding] GO:0030674 [protein binding, bridging] GO:0033268 [node of Ranvier] GO:0042383 [sarcolemma] GO:0043001 [Golgi to plasma membrane protein transport] GO:0043034 [costamere] GO:0043194 [axon initial segment] GO:0043266 [regulation of potassium ion transport] GO:0044325 [ion channel binding] GO:0045184 [establishment of protein localization] GO:0045211 [postsynaptic membrane] GO:0045296 [cadherin binding] GO:0045838 [positive regulation of membrane potential] GO:0071286 [cellular response to magnesium ion] GO:0071709 [membrane assembly] GO:0072659 [protein localization to plasma membrane] GO:0072660 [maintenance of protein location in plasma membrane] GO:0072661 [protein targeting to plasma membrane] GO:1900827 [positive regulation of membrane depolarization during cardiac muscle cell action potential] GO:1902260 [negative regulation of delayed rectifier potassium channel activity] GO:2000651 [positive regulation of sodium ion transmembrane transporter activity]
Predicted intracellular proteins Plasma proteins Cancer-related genes Mutated cancer genes Disease related genes Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0000281 [mitotic cytokinesis] GO:0005200 [structural constituent of cytoskeleton] GO:0005515 [protein binding] GO:0005764 [lysosome] GO:0005783 [endoplasmic reticulum] GO:0005794 [Golgi apparatus] GO:0005886 [plasma membrane] GO:0005923 [bicellular tight junction] GO:0007009 [plasma membrane organization] GO:0007016 [cytoskeletal anchoring at plasma membrane] GO:0007165 [signal transduction] GO:0007409 [axonogenesis] GO:0008092 [cytoskeletal protein binding] GO:0009925 [basal plasma membrane] GO:0009986 [cell surface] GO:0010628 [positive regulation of gene expression] GO:0010765 [positive regulation of sodium ion transport] GO:0010960 [magnesium ion homeostasis] GO:0014704 [intercalated disc] GO:0014731 [spectrin-associated cytoskeleton] GO:0016323 [basolateral plasma membrane] GO:0016328 [lateral plasma membrane] GO:0019228 [neuronal action potential] GO:0030315 [T-tubule] GO:0030507 [spectrin binding] GO:0030674 [protein binding, bridging] GO:0033268 [node of Ranvier] GO:0042383 [sarcolemma] GO:0043001 [Golgi to plasma membrane protein transport] GO:0043034 [costamere] GO:0043194 [axon initial segment] GO:0043266 [regulation of potassium ion transport] GO:0044325 [ion channel binding] GO:0045184 [establishment of protein localization] GO:0045211 [postsynaptic membrane] GO:0045296 [cadherin binding] GO:0045838 [positive regulation of membrane potential] GO:0071286 [cellular response to magnesium ion] GO:0071709 [membrane assembly] GO:0072659 [protein localization to plasma membrane] GO:0072660 [maintenance of protein location in plasma membrane] GO:0072661 [protein targeting to plasma membrane] GO:1900827 [positive regulation of membrane depolarization during cardiac muscle cell action potential] GO:1902260 [negative regulation of delayed rectifier potassium channel activity] GO:2000651 [positive regulation of sodium ion transmembrane transporter activity]
Predicted intracellular proteins Plasma proteins Cancer-related genes Mutated cancer genes Disease related genes Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0000281 [mitotic cytokinesis] GO:0005200 [structural constituent of cytoskeleton] GO:0005515 [protein binding] GO:0005764 [lysosome] GO:0005783 [endoplasmic reticulum] GO:0005794 [Golgi apparatus] GO:0005886 [plasma membrane] GO:0005923 [bicellular tight junction] GO:0007009 [plasma membrane organization] GO:0007016 [cytoskeletal anchoring at plasma membrane] GO:0007165 [signal transduction] GO:0007409 [axonogenesis] GO:0008092 [cytoskeletal protein binding] GO:0009925 [basal plasma membrane] GO:0009986 [cell surface] GO:0010628 [positive regulation of gene expression] GO:0010765 [positive regulation of sodium ion transport] GO:0010960 [magnesium ion homeostasis] GO:0014704 [intercalated disc] GO:0014731 [spectrin-associated cytoskeleton] GO:0016323 [basolateral plasma membrane] GO:0016328 [lateral plasma membrane] GO:0019228 [neuronal action potential] GO:0030315 [T-tubule] GO:0030507 [spectrin binding] GO:0030674 [protein binding, bridging] GO:0033268 [node of Ranvier] GO:0042383 [sarcolemma] GO:0043001 [Golgi to plasma membrane protein transport] GO:0043034 [costamere] GO:0043194 [axon initial segment] GO:0043266 [regulation of potassium ion transport] GO:0044325 [ion channel binding] GO:0045184 [establishment of protein localization] GO:0045211 [postsynaptic membrane] GO:0045296 [cadherin binding] GO:0045838 [positive regulation of membrane potential] GO:0071286 [cellular response to magnesium ion] GO:0071709 [membrane assembly] GO:0072659 [protein localization to plasma membrane] GO:0072660 [maintenance of protein location in plasma membrane] GO:0072661 [protein targeting to plasma membrane] GO:1900827 [positive regulation of membrane depolarization during cardiac muscle cell action potential] GO:1902260 [negative regulation of delayed rectifier potassium channel activity] GO:2000651 [positive regulation of sodium ion transmembrane transporter activity]