We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
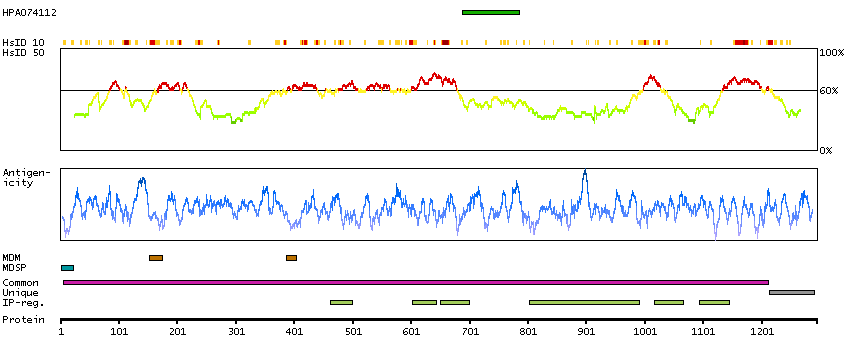
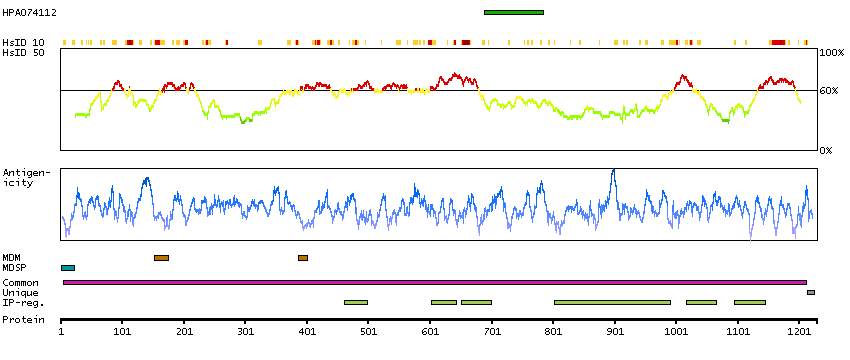
Astrotactin is a neuronal adhesion molecule required for glial-guided migration of young postmitotic neuroblasts in cortical regions of developing brain, including cerebrum, hippocampus, cerebellum, and olfactory bulb (Fink et al., 1995).[supplied by OMIM, Jun 2009]