We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
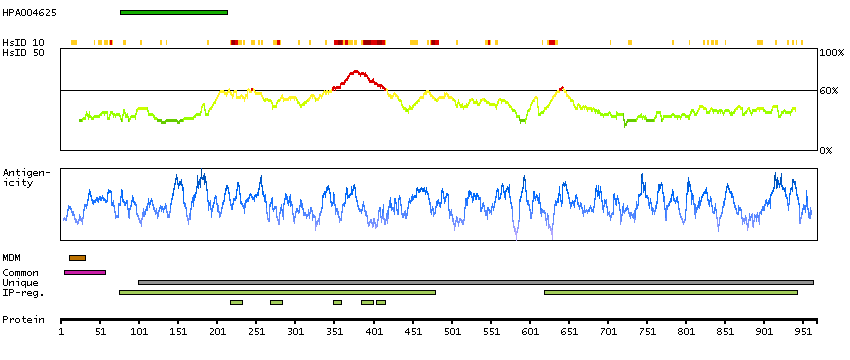
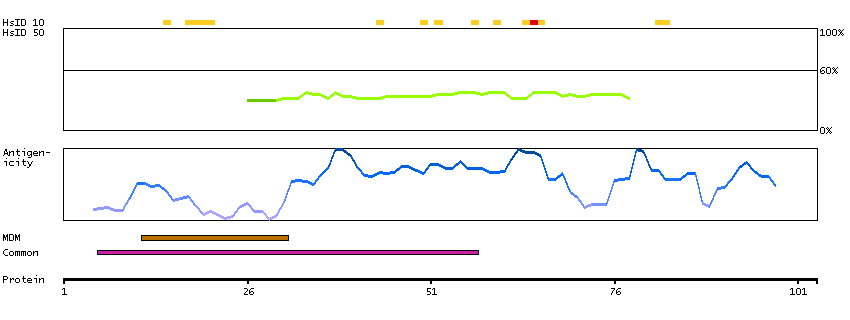
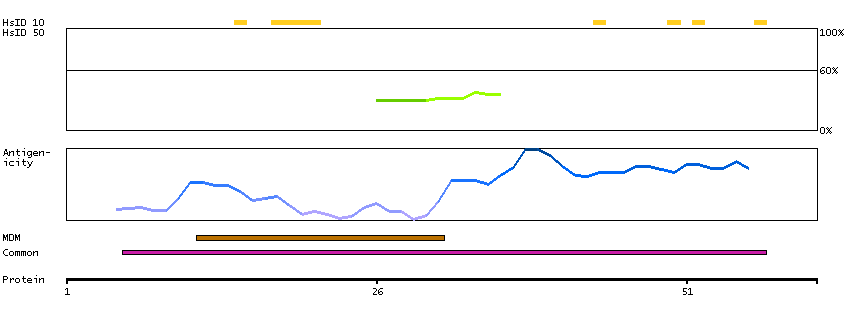
Aminopeptidase N is located in the small-intestinal and renal microvillar membrane, and also in other plasma membranes. In the small intestine aminopeptidase N plays a role in the final digestion of peptides generated from hydrolysis of proteins by gastric and pancreatic proteases. Its function in proximal tubular epithelial cells and other cell types is less clear. The large extracellular carboxyterminal domain contains a pentapeptide consensus sequence characteristic of members of the zinc-binding metalloproteinase superfamily. Sequence comparisons with known enzymes of this class showed that CD13 and aminopeptidase N are identical. The latter enzyme was thought to be involved in the metabolism of regulatory peptides by diverse cell types, including small intestinal and renal tubular epithelial cells, macrophages, granulocytes, and synaptic membranes from the CNS. Human aminopeptidase N is a receptor for one strain of human coronavirus that is an important cause of upper respiratory tract infections. Defects in this gene appear to be a cause of various types of leukemia or lymphoma. [provided by RefSeq, Jul 2008]