We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Several cases of hepatocellular carcinomas along with a few cases of renal and prostate cancers displayed moderate cytoplasmic staining and in a few cases nuclear positivity. Other cancers were weakly stained or negative.
GENE INFORMATION
Gene name
ADRA1D (HGNC Symbol)
Synonyms
ADRA1, ADRA1A, ADRA1R
Description
Adrenoceptor alpha 1D (HGNC Symbol)
Entrez gene summary
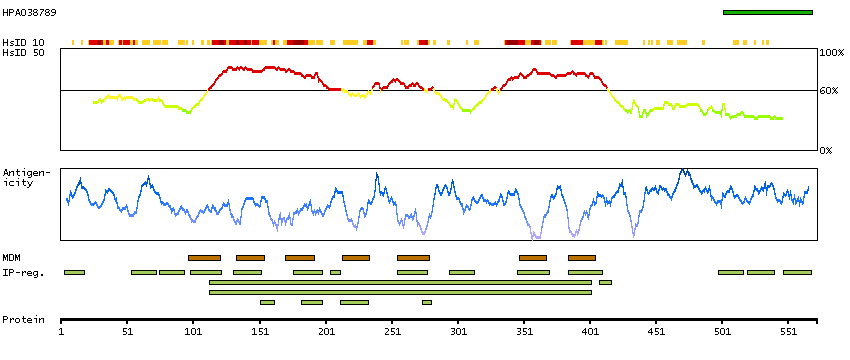
Alpha-1-adrenergic receptors (alpha-1-ARs) are members of the G protein-coupled receptor superfamily. They activate mitogenic responses and regulate growth and proliferation of many cells. There are 3 alpha-1-AR subtypes: alpha-1A, -1B and -1D, all of which signal through the Gq/11 family of G-proteins and different subtypes show different patterns of activation. This gene encodes alpha-1D-adrenergic receptor. Similar to alpha-1B-adrenergic receptor gene, this gene comprises 2 exons and a single intron that interrupts the coding region. [provided by RefSeq, Jul 2008]