We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
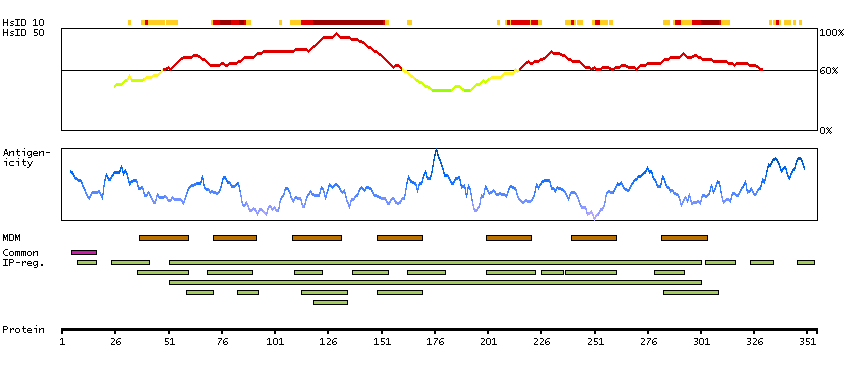
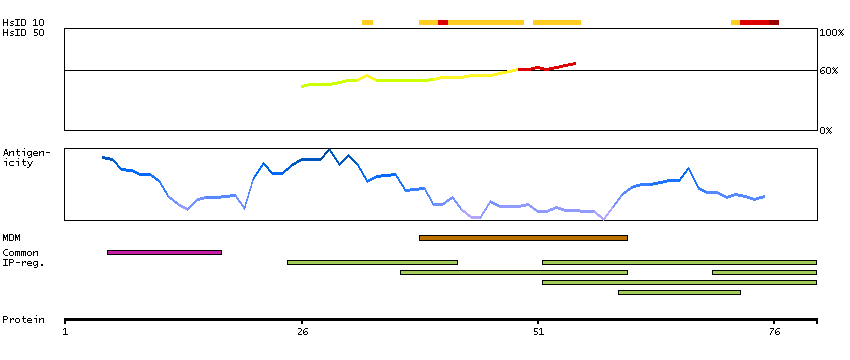
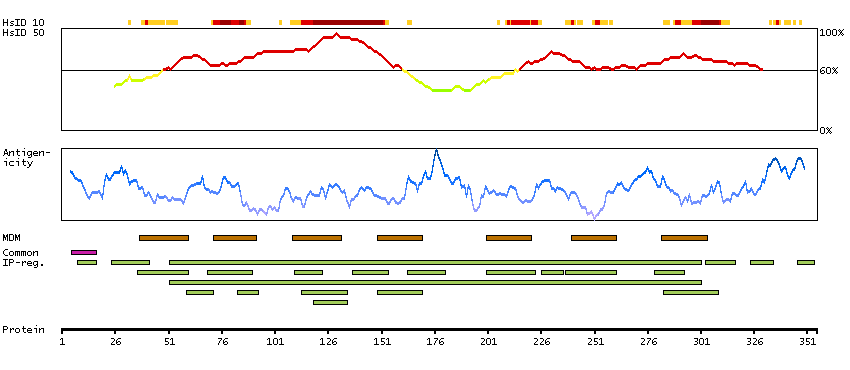
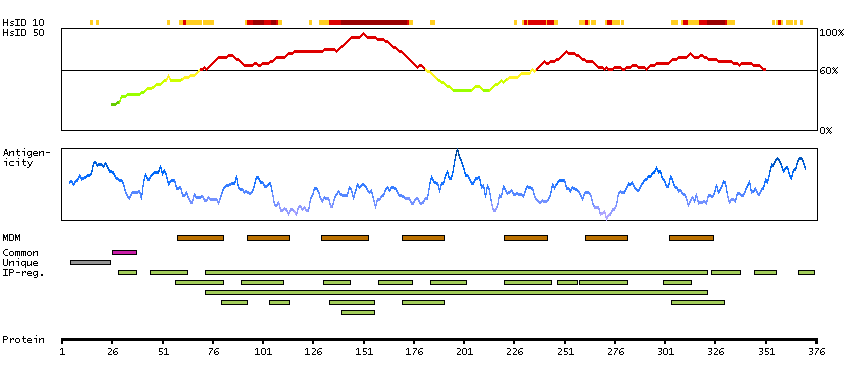
The protein encoded by this gene is a receptor for C-C type chemokines. It belongs to family 1 of the G protein-coupled receptors. This receptor binds and responds to a variety of chemokines, including eotaxin (CCL11), eotaxin-3 (CCL26), MCP-3 (CCL7), MCP-4 (CCL13), and RANTES (CCL5). It is highly expressed in eosinophils and basophils, and is also detected in TH1 and TH2 cells, as well as in airway epithelial cells. This receptor may contribute to the accumulation and activation of eosinophils and other inflammatory cells in the allergic airway. It is also known to be an entry co-receptor for HIV-1. This gene and seven other chemokine receptor genes form a chemokine receptor gene cluster on the chromosomal region 3p21. Alternatively spliced transcript variants have been described. [provided by RefSeq, Sep 2009]