We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
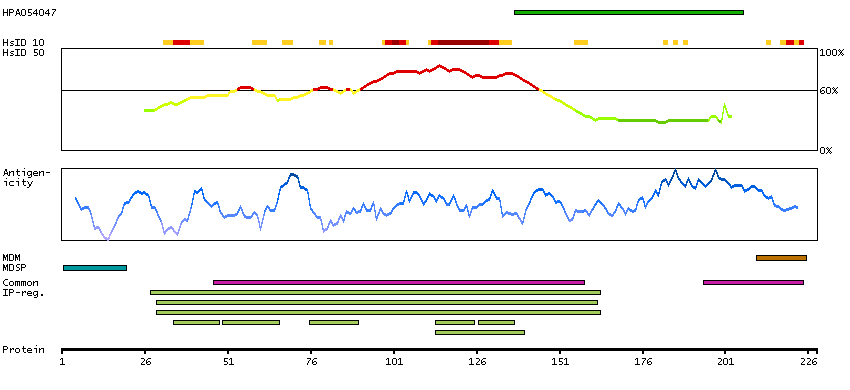
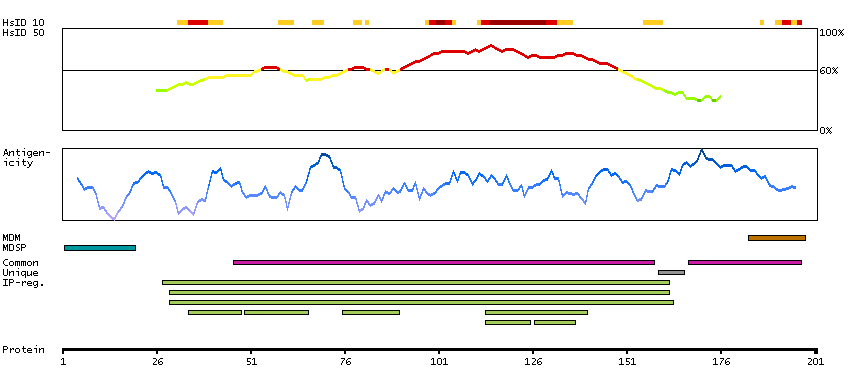
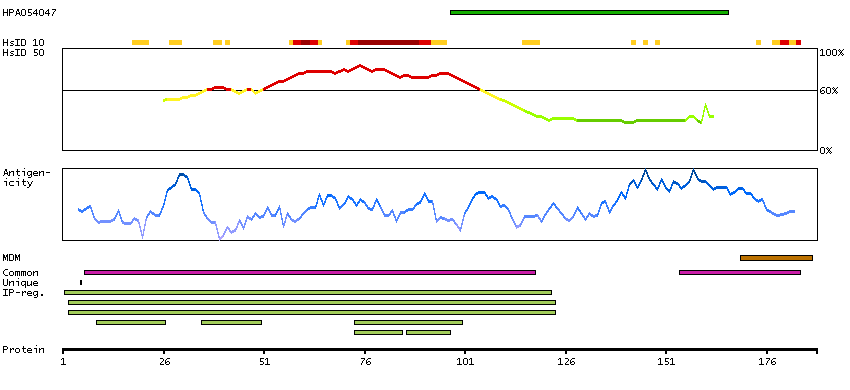
Ephrin-A5, a member of the ephrin gene family, prevents axon bundling in cocultures of cortical neurons with astrocytes, a model of late stage nervous system development and differentiation. The EPH and EPH-related receptors comprise the largest subfamily of receptor protein-tyrosine kinases and have been implicated in mediating developmental events, particularly in the nervous system. EPH receptors typically have a single kinase domain and an extracellular region containing a Cys-rich domain and 2 fibronectin type III repeats. The ephrin ligands and receptors have been named by the Eph Nomenclature Committee (1997). Based on their structures and sequence relationships, ephrins are divided into the ephrin-A (EFNA) class, which are anchored to the membrane by a glycosylphosphatidylinositol linkage, and the ephrin-B (EFNB) class, which are transmembrane proteins. The Eph family of receptors are similarly divided into 2 groups based on the similarity of their extracellular domain sequences and their affinities for binding ephrin-A and ephrin-B ligands. [provided by RefSeq, Jul 2008]