We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Caution, targets protein from more than one gene. Antibody staining in cells/structures not annotated, view images. Tissue location of RNA and protein might differ and correlation is complex.
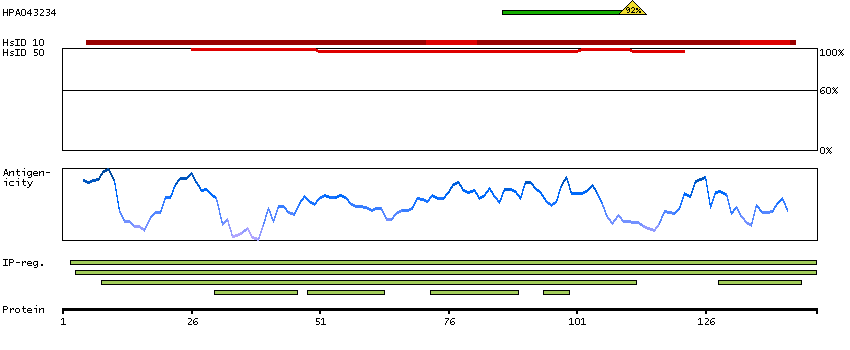
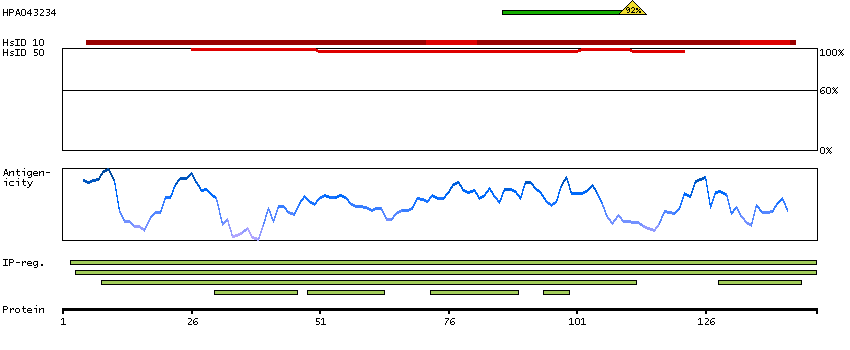
The gamma globin genes (HBG1 and HBG2) are normally expressed in the fetal liver, spleen and bone marrow. Two gamma chains together with two alpha chains constitute fetal hemoglobin (HbF) which is normally replaced by adult hemoglobin (HbA) at birth. In some beta-thalassemias and related conditions, gamma chain production continues into adulthood. The two types of gamma chains differ at residue 136 where glycine is found in the G-gamma product (HBG2) and alanine is found in the A-gamma product (HBG1). The former is predominant at birth. The order of the genes in the beta-globin cluster is: 5'- epsilon -- gamma-G -- gamma-A -- delta -- beta--3'. [provided by RefSeq, Jul 2008]