We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
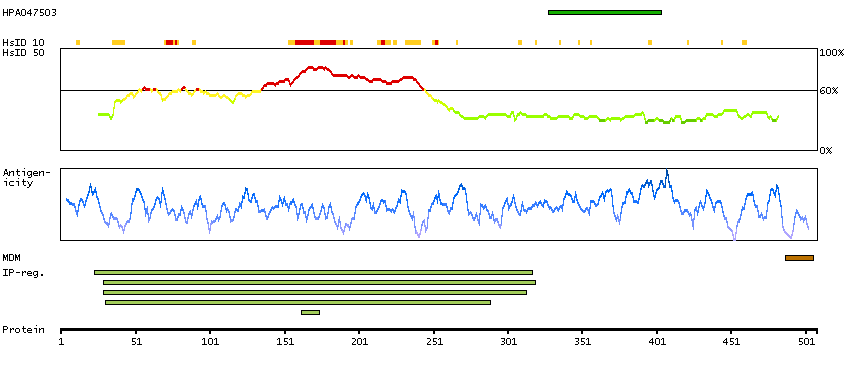
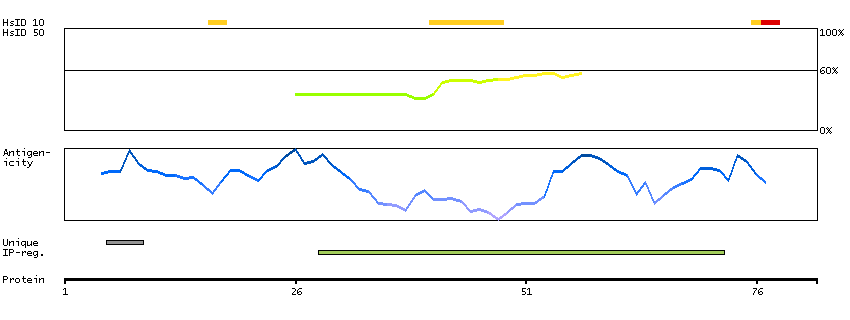
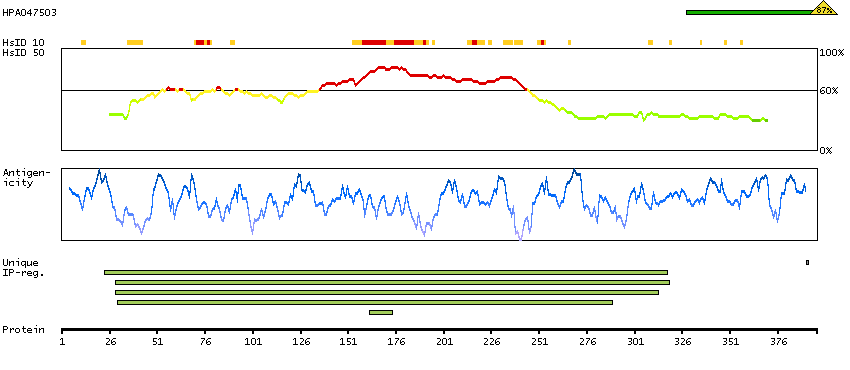
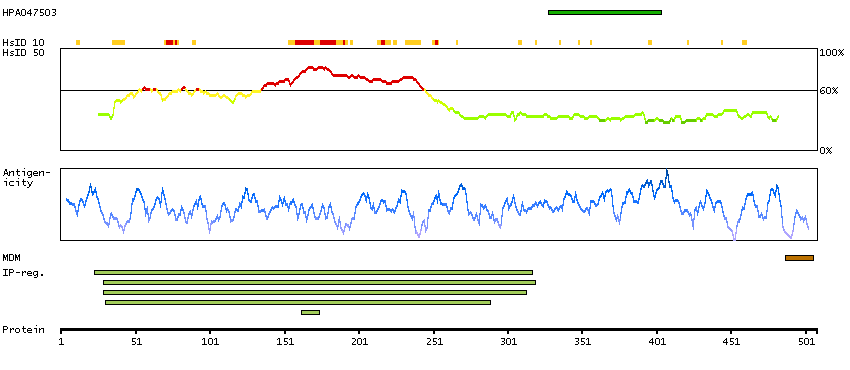
This gene encodes a member of the vaccinia-related kinase (VRK) family of serine/threonine protein kinases. The encoded protein acts as an effector of signaling pathways that regulate apoptosis and tumor cell growth. Variants in this gene have been associated with schizophrenia. Alternative splicing results in multiple transcript variants that differ in their subcellular localization and biological activity. [provided by RefSeq, Jan 2014]
Enzymes ENZYME proteins Transferases Kinases CK1 Ser/Thr protein kinases Predicted intracellular proteins Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)