We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
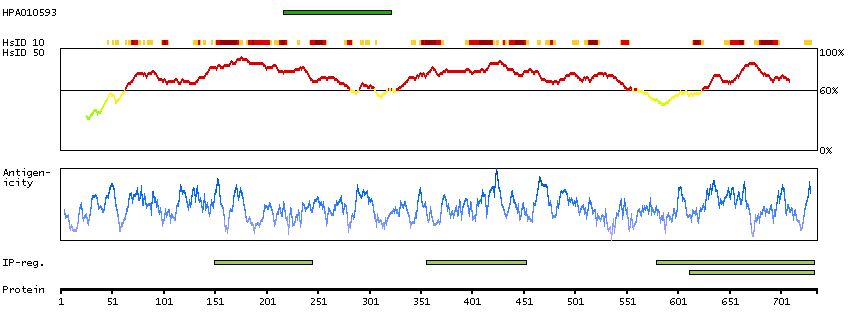
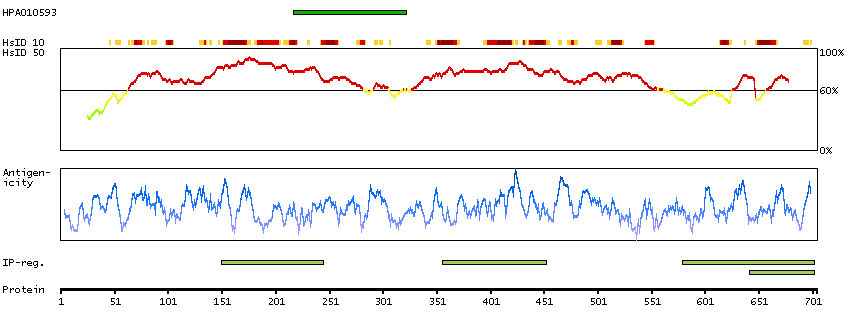
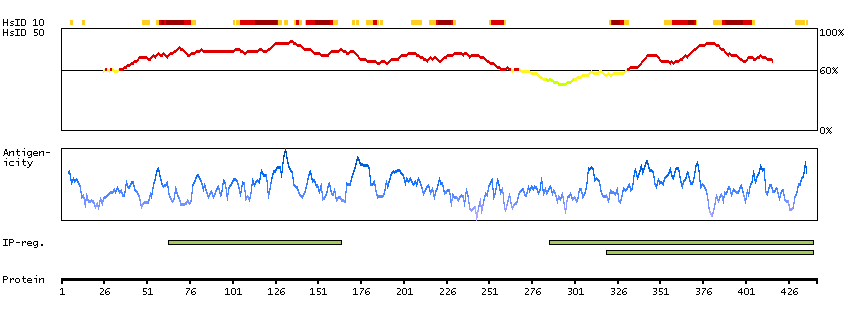
This gene encodes a type II transmembrane glycoprotein belonging to the M28 peptidase family. The protein acts as a glutamate carboxypeptidase on different alternative substrates, including the nutrient folate and the neuropeptide N-acetyl-l-aspartyl-l-glutamate and is expressed in a number of tissues such as prostate, central and peripheral nervous system and kidney. A mutation in this gene may be associated with impaired intestinal absorption of dietary folates, resulting in low blood folate levels and consequent hyperhomocysteinemia. Expression of this protein in the brain may be involved in a number of pathological conditions associated with glutamate excitotoxicity. In the prostate the protein is up-regulated in cancerous cells and is used as an effective diagnostic and prognostic indicator of prostate cancer. This gene likely arose from a duplication event of a nearby chromosomal region. Alternative splicing gives rise to multiple transcript variants encoding several different isoforms. [provided by RefSeq, Jul 2010]
Enzymes ENZYME proteins Hydrolases Peptidases Metallopeptidases MEMSAT3 predicted membrane proteins Predicted intracellular proteins Plasma proteins Cancer-related genes Candidate cancer biomarkers FDA approved drug targets Biotech drugs Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)