We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
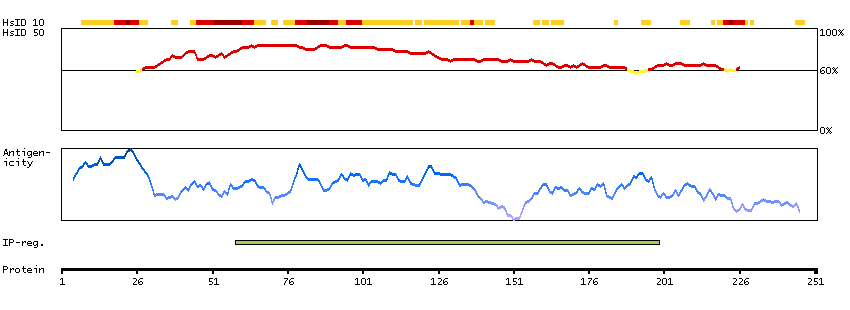
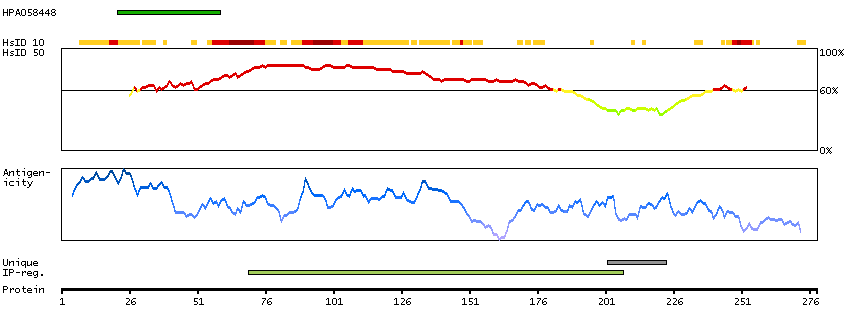
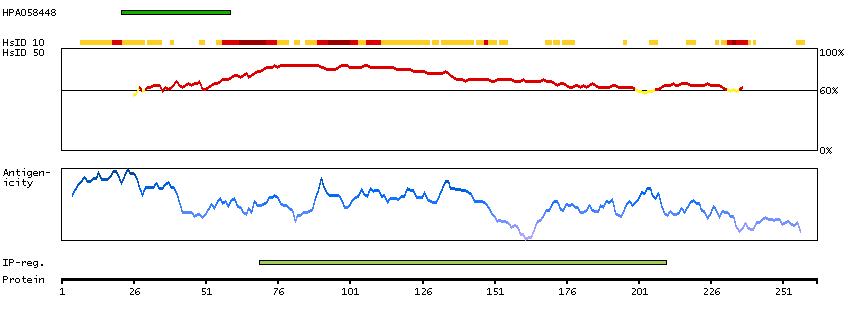
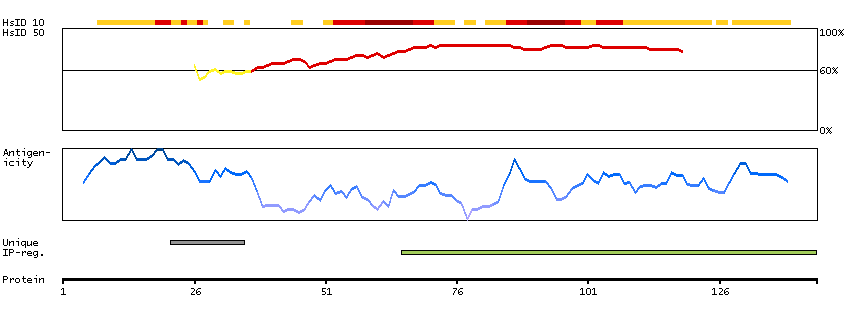
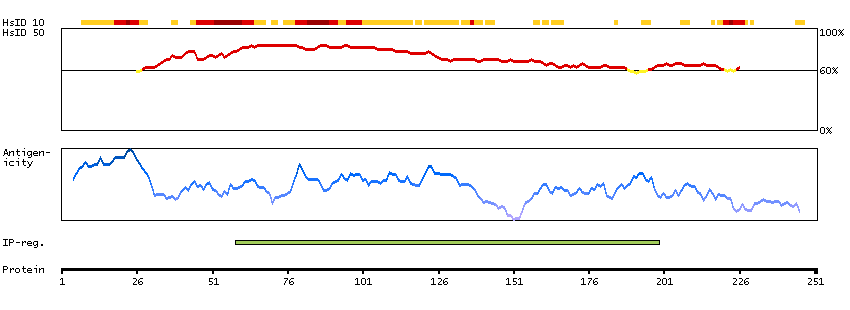
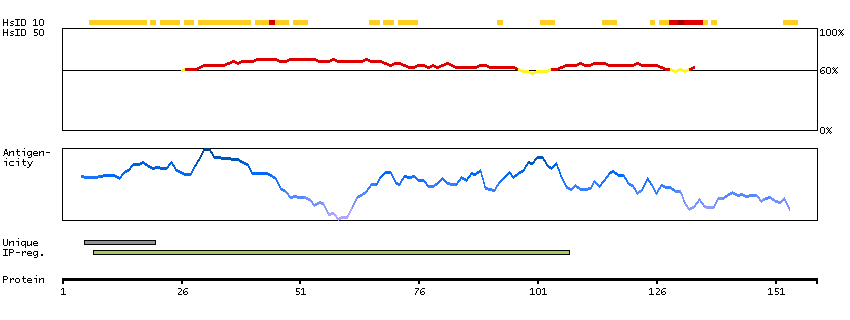
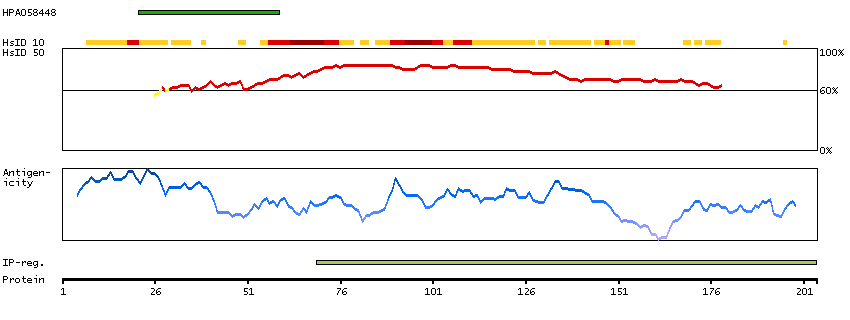
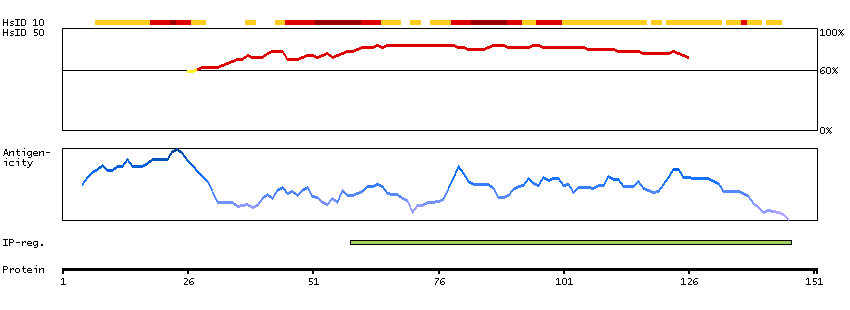
This gene encodes a protein that is a subunit of troponin, which is a regulatory complex located on the thin filament of the sarcomere. This complex regulates striated muscle contraction in response to fluctuations in intracellular calcium concentration. This complex is composed of three subunits: troponin C, which binds calcium, troponin T, which binds tropomyosin, and troponin I, which is an inhibitory subunit. This protein is the slow skeletal troponin T subunit. Mutations in this gene cause nemaline myopathy type 5, also known as Amish nemaline myopathy, a neuromuscular disorder characterized by muscle weakness and rod-shaped, or nemaline, inclusions in skeletal muscle fibers which affects infants, resulting in death due to respiratory insufficiency, usually in the second year. Multiple transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, Jul 2008]