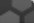We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Follicular adenoma carcinoma of thyroid showed strong cytoplasmic staining. Occasional cases of cholangiocarcinoma, prostate, endometrial and pancreatic cancers exhibited moderate to strong positivity. Remaining cancer tissues were negative.
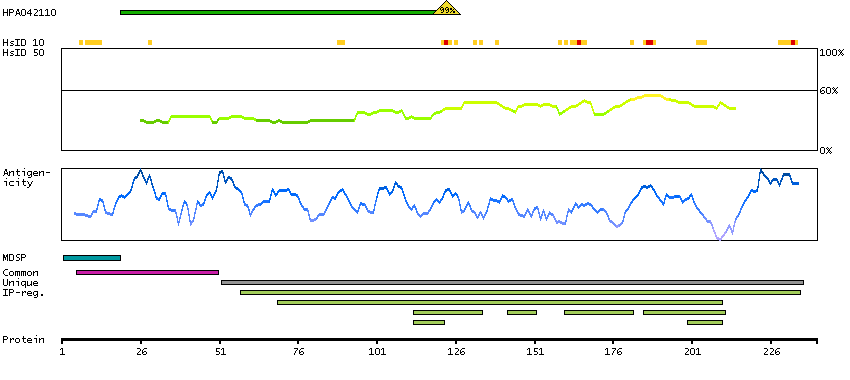
This gene encodes a member of the superoxide dismutase (SOD) protein family. SODs are antioxidant enzymes that catalyze the conversion of superoxide radicals into hydrogen peroxide and oxygen, which may protect the brain, lungs, and other tissues from oxidative stress. Proteolytic processing of the encoded protein results in the formation of two distinct homotetramers that differ in their ability to interact with the extracellular matrix (ECM). Homotetramers consisting of the intact protein, or type C subunit, exhibit high affinity for heparin and are anchored to the ECM. Homotetramers consisting of a proteolytically cleaved form of the protein, or type A subunit, exhibit low affinity for heparin and do not interact with the ECM. A mutation in this gene may be associated with increased heart disease risk. [provided by RefSeq, Oct 2015]