We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
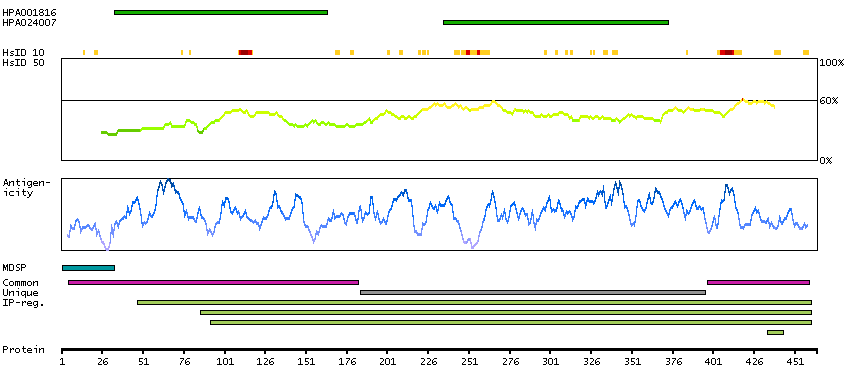
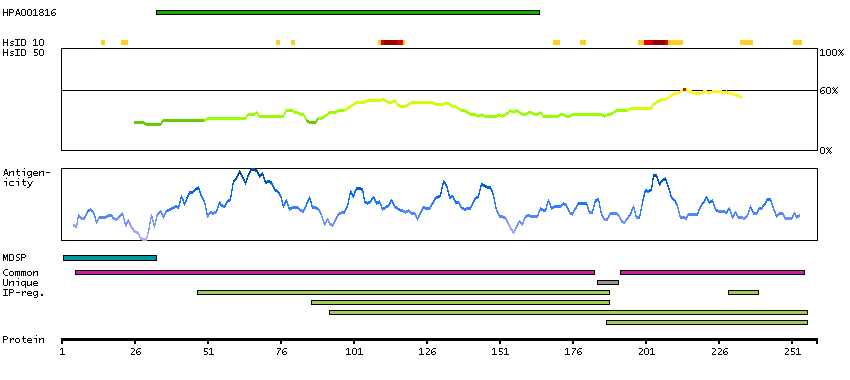
Serpin peptidase inhibitor, clade C (antithrombin), member 1 (HGNC Symbol)
Entrez gene summary
The protein encoded by this gene is a plasma protease inhibitor and a member of the serpin superfamily. This protein inhibits thrombin as well as other activated serine proteases of the coagulation system, and it regulates the blood coagulation cascade. The protein includes two functional domains: the heparin binding-domain at the N-terminus of the mature protein, and the reactive site domain at the C-terminus. The inhibitory activity is enhanced by the presence of heparin. More than 120 mutations have been identified for this gene, many of which are known to cause antithrombin-III deficiency. [provided by RefSeq, Jul 2009]