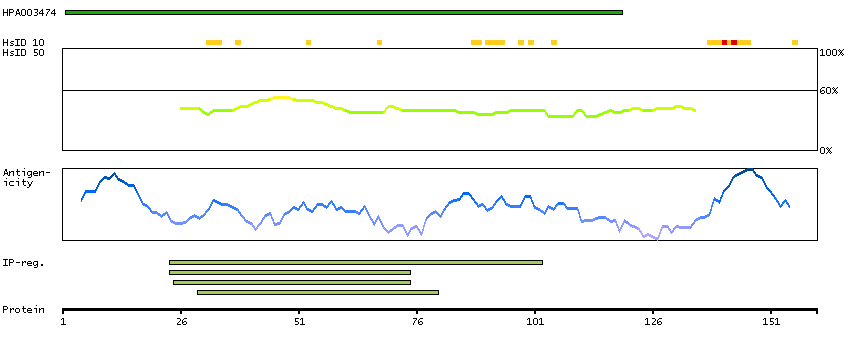
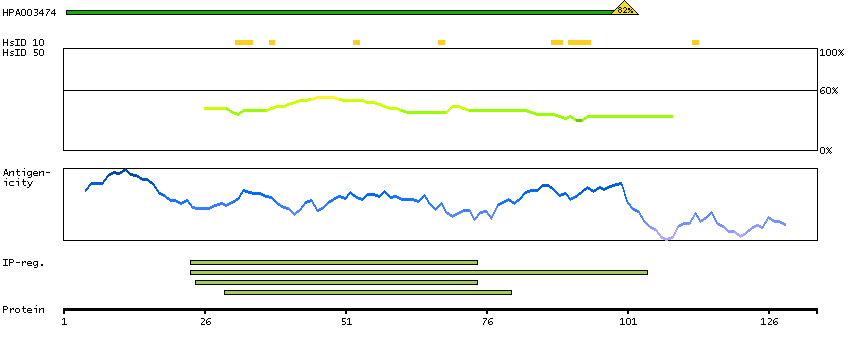
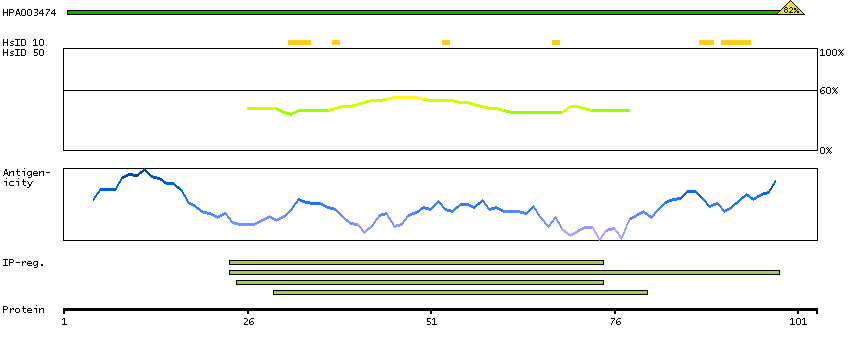
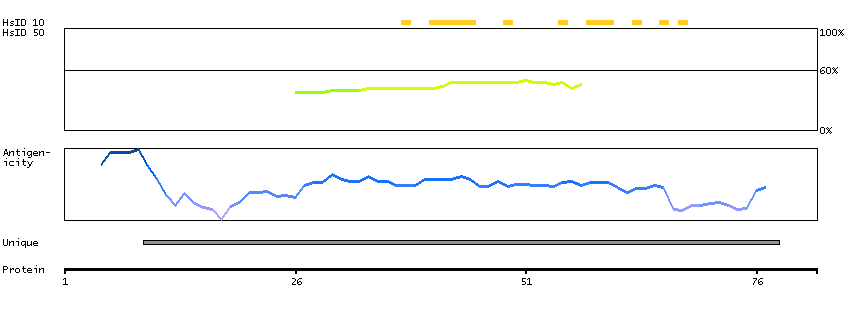
We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
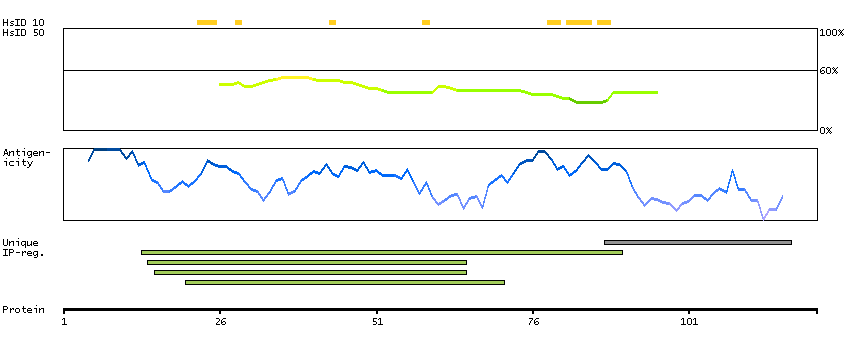
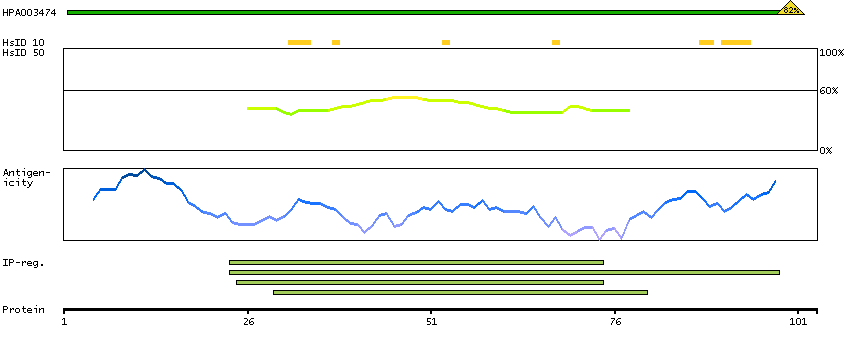
The protein encoded by this gene is a member of the basic helix-loop-helix leucine zipper (bHLHZ) family of transcription factors. It is able to form homodimers and heterodimers with other family members, which include Mad, Mxi1 and Myc. Myc is an oncoprotein implicated in cell proliferation, differentiation and apoptosis. The homodimers and heterodimers compete for a common DNA target site (the E box) and rearrangement among these dimer forms provides a complex system of transcriptional regulation. Mutations of this gene have been reported to be associated with hereditary pheochromocytoma. A pseudogene of this gene is located on the long arm of chromosome 7. Alternative splicing results in multiple transcript variants. [provided by RefSeq, Aug 2012]