We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Calcium/calmodulin-dependent protein kinase I (HGNC Symbol)
Entrez gene summary
Calcium/calmodulin-dependent protein kinase I is expressed in many tissues and is a component of a calmodulin-dependent protein kinase cascade. Calcium/calmodulin directly activates calcium/calmodulin-dependent protein kinase I by binding to the enzyme and indirectly promotes the phosphorylation and synergistic activation of the enzyme by calcium/calmodulin-dependent protein kinase I kinase. [provided by RefSeq, Jul 2008]
Q14012 [Direct mapping] Calcium/calmodulin-dependent protein kinase type 1 B0YIY3 [Target identity:100%; Query identity:100%] Calcium/calmodulin-dependent protein kinase I, isoform CRA_a; Calcium/calmodulin-dependent protein kinase type 1; cDNA, FLJ95825, Homo sapiens calcium/calmodulin-dependent protein kinase I (CAMK1),mRNA
Show all
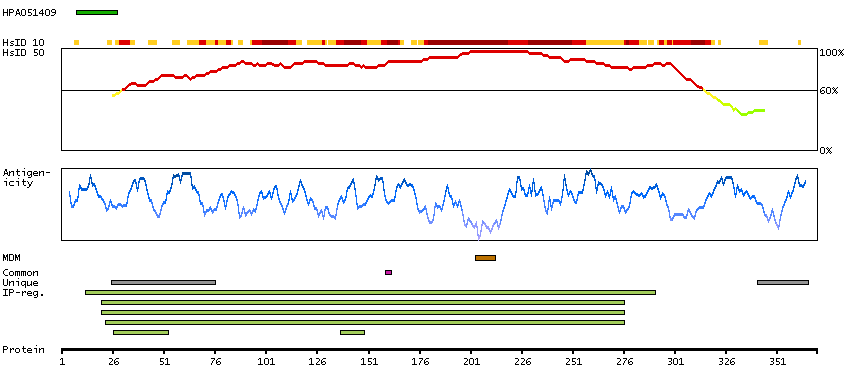
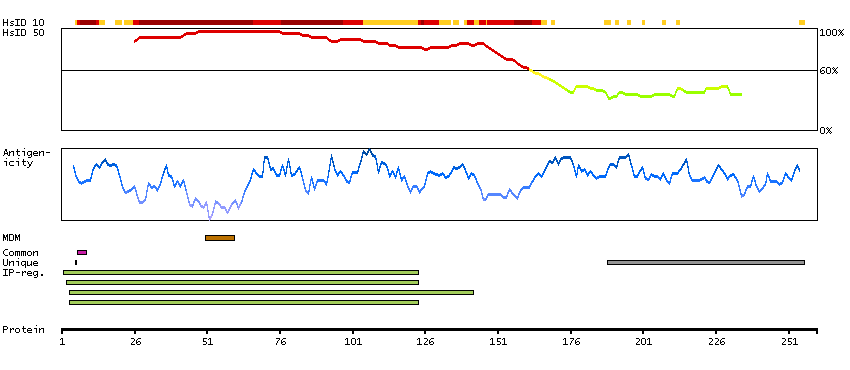
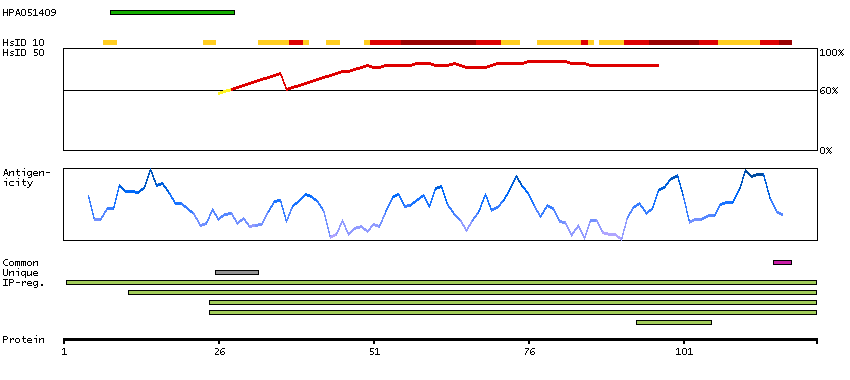
Enzymes ENZYME proteins Transferases Kinases CAMK Ser/Thr protein kinases Predicted membrane proteins Prediction method-based Membrane proteins predicted by MDM MEMSAT-SVM predicted membrane proteins SCAMPI predicted membrane proteins SPOCTOPUS predicted membrane proteins THUMBUP predicted membrane proteins # TM segments-based 1TM proteins predicted by MDM Plasma proteins Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0004672 [protein kinase activity] GO:0004683 [calmodulin-dependent protein kinase activity] GO:0005515 [protein binding] GO:0005516 [calmodulin binding] GO:0005524 [ATP binding] GO:0005622 [intracellular] GO:0005634 [nucleus] GO:0005737 [cytoplasm] GO:0006468 [protein phosphorylation] GO:0006913 [nucleocytoplasmic transport] GO:0007049 [cell cycle] GO:0007165 [signal transduction] GO:0010976 [positive regulation of neuron projection development] GO:0032091 [negative regulation of protein binding] GO:0032880 [regulation of protein localization] GO:0033138 [positive regulation of peptidyl-serine phosphorylation] GO:0043393 [regulation of protein binding] GO:0045944 [positive regulation of transcription from RNA polymerase II promoter] GO:0046827 [positive regulation of protein export from nucleus] GO:0051147 [regulation of muscle cell differentiation] GO:0051149 [positive regulation of muscle cell differentiation] GO:0051835 [positive regulation of synapse structural plasticity] GO:0060143 [positive regulation of syncytium formation by plasma membrane fusion] GO:0060999 [positive regulation of dendritic spine development] GO:0071902 [positive regulation of protein serine/threonine kinase activity] GO:1901985 [positive regulation of protein acetylation]