We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
RNA tissue category: Group enriched (esophagus, tonsil, cervix, uterine)
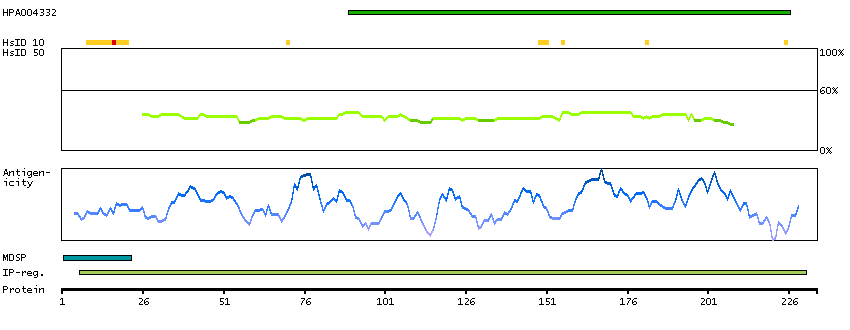
GENE INFORMATION
Gene name
FGFBP1 (HGNC Symbol)
Synonyms
FGFBP, HBP17
Description
Fibroblast growth factor binding protein 1 (HGNC Symbol)
Entrez gene summary
This gene encodes a secreted fibroblast growth factor carrier protein. The encoded protein plays a critical role in cell proliferation, differentiation and migration by binding to fibroblast growth factors and potentiating their biological effects on target cells. The encoded protein may also play a role in tumor growth as an angiogenic switch molecule, and expression of this gene has been associated with several types of cancer including pancreatic and colorectal adenocarcinoma. A pseudogene of this gene is also located on the short arm of chromosome 4. [provided by RefSeq, Nov 2011]