We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
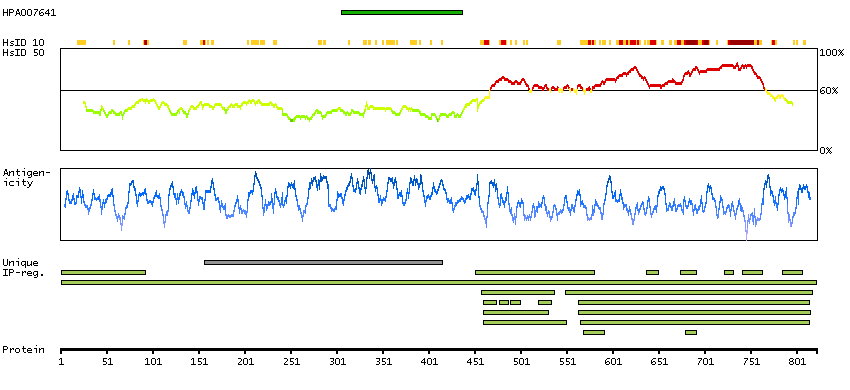
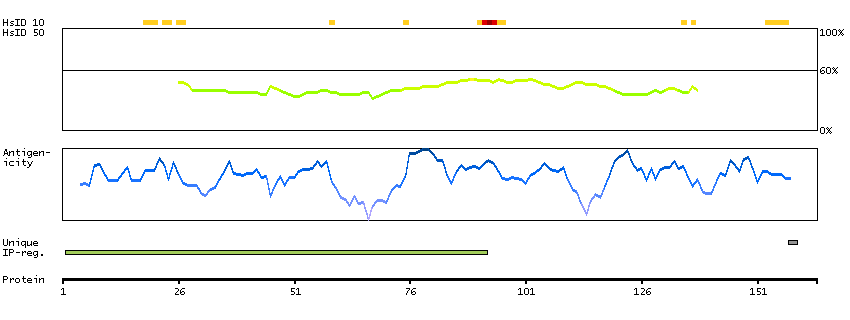
Fer (fps/fes related) tyrosine kinase (HGNC Symbol)
Entrez gene summary
The protein encoded by this gene is a member of the FPS/FES family of non-transmembrane receptor tyrosine kinases. It regulates cell-cell adhesion and mediates signaling from the cell surface to the cytoskeleton via growth factor receptors. Alternative splicing results in multiple transcript variants. A related pseudogene has been identified on chromosome X. [provided by RefSeq, Apr 2015]
Enzymes ENZYME proteins Transferases Kinases Tyr protein kinases Predicted intracellular proteins Plasma proteins Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)