We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
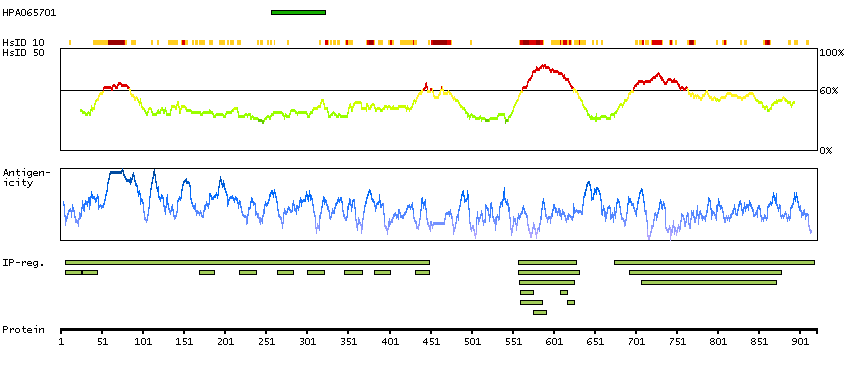
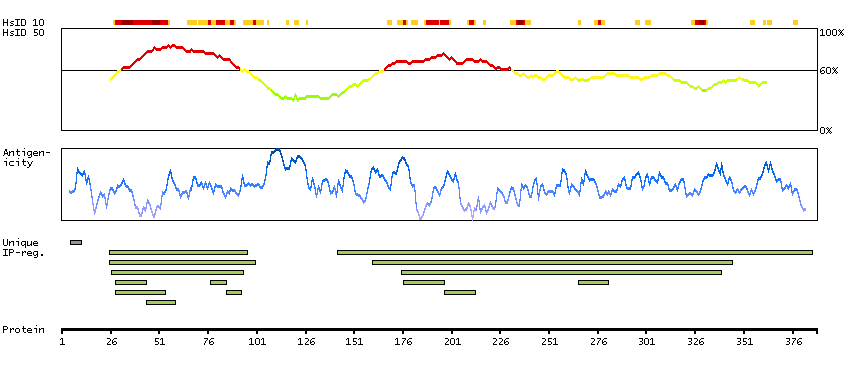
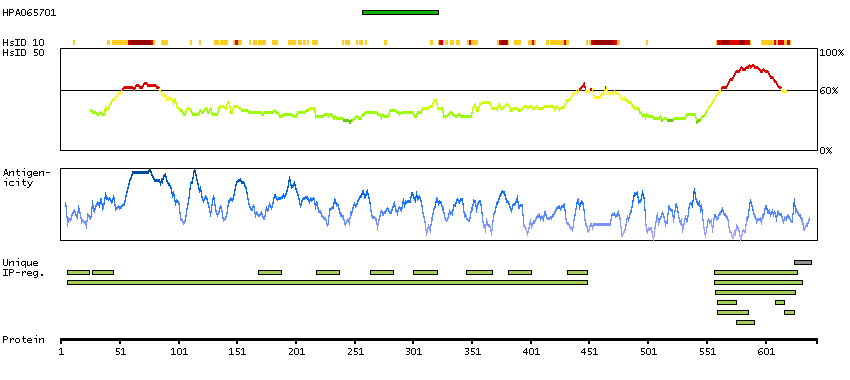
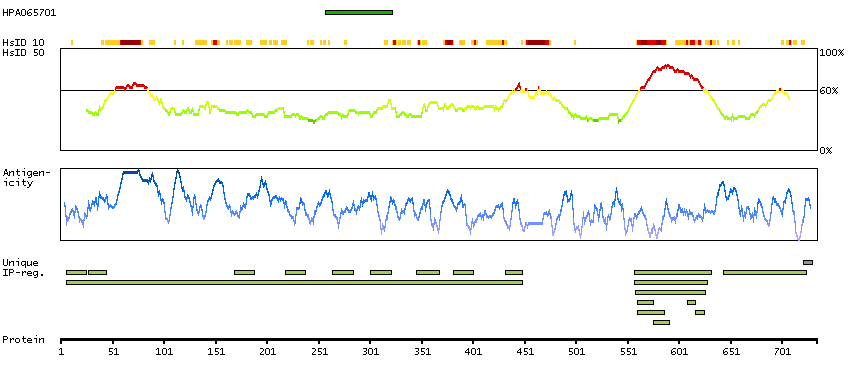
The androgen receptor gene is more than 90 kb long and codes for a protein that has 3 major functional domains: the N-terminal domain, DNA-binding domain, and androgen-binding domain. The protein functions as a steroid-hormone activated transcription factor. Upon binding the hormone ligand, the receptor dissociates from accessory proteins, translocates into the nucleus, dimerizes, and then stimulates transcription of androgen responsive genes. This gene contains 2 polymorphic trinucleotide repeat segments that encode polyglutamine and polyglycine tracts in the N-terminal transactivation domain of its protein. Expansion of the polyglutamine tract causes spinal bulbar muscular atrophy (Kennedy disease). Mutations in this gene are also associated with complete androgen insensitivity (CAIS). Two alternatively spliced variants encoding distinct isoforms have been described. [provided by RefSeq, Jul 2008]
Phobius predicted membrane proteins THUMBUP predicted membrane proteins Predicted intracellular proteins Cancer-related genes Mutational cancer driver genes Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0001701 [in utero embryonic development] GO:0003073 [regulation of systemic arterial blood pressure] GO:0003382 [epithelial cell morphogenesis] GO:0003677 [DNA binding] GO:0003700 [transcription factor activity, sequence-specific DNA binding] GO:0004882 [androgen receptor activity] GO:0005496 [steroid binding] GO:0005515 [protein binding] GO:0005634 [nucleus] GO:0005886 [plasma membrane] GO:0006351 [transcription, DNA-templated] GO:0006355 [regulation of transcription, DNA-templated] GO:0006357 [regulation of transcription from RNA polymerase II promoter] GO:0007283 [spermatogenesis] GO:0007338 [single fertilization] GO:0008270 [zinc ion binding] GO:0008584 [male gonad development] GO:0009566 [fertilization] GO:0009987 [cellular process] GO:0010468 [regulation of gene expression] GO:0019102 [male somatic sex determination] GO:0030521 [androgen receptor signaling pathway] GO:0033148 [positive regulation of intracellular estrogen receptor signaling pathway] GO:0033327 [Leydig cell differentiation] GO:0035264 [multicellular organism growth] GO:0043401 [steroid hormone mediated signaling pathway] GO:0043410 [positive regulation of MAPK cascade] GO:0043565 [sequence-specific DNA binding] GO:0043568 [positive regulation of insulin-like growth factor receptor signaling pathway] GO:0048608 [reproductive structure development] GO:0048638 [regulation of developmental growth] GO:0048645 [organ formation] GO:0048808 [male genitalia morphogenesis] GO:0050680 [negative regulation of epithelial cell proliferation] GO:0050790 [regulation of catalytic activity] GO:0060520 [activation of prostate induction by androgen receptor signaling pathway] GO:0060571 [morphogenesis of an epithelial fold] GO:0060599 [lateral sprouting involved in mammary gland duct morphogenesis] GO:0060685 [regulation of prostatic bud formation] GO:0060736 [prostate gland growth] GO:0060740 [prostate gland epithelium morphogenesis] GO:0060742 [epithelial cell differentiation involved in prostate gland development] GO:0060748 [tertiary branching involved in mammary gland duct morphogenesis] GO:0060749 [mammary gland alveolus development] GO:0061458 [reproductive system development] GO:0070974 [POU domain binding] GO:0072520 [seminiferous tubule development]
Nuclear receptors THUMBUP predicted membrane proteins Predicted intracellular proteins Plasma proteins Transcription factors Zinc-coordinating DNA-binding domains Cancer-related genes Candidate cancer biomarkers Mutational cancer driver genes Disease related genes FDA approved drug targets Small molecule drugs Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0000790 [nuclear chromatin] GO:0000978 [RNA polymerase II core promoter proximal region sequence-specific DNA binding] GO:0001077 [transcriptional activator activity, RNA polymerase II core promoter proximal region sequence-specific binding] GO:0001085 [RNA polymerase II transcription factor binding] GO:0003677 [DNA binding] GO:0003682 [chromatin binding] GO:0003700 [transcription factor activity, sequence-specific DNA binding] GO:0004879 [RNA polymerase II transcription factor activity, ligand-activated sequence-specific DNA binding] GO:0004882 [androgen receptor activity] GO:0005102 [receptor binding] GO:0005497 [androgen binding] GO:0005515 [protein binding] GO:0005634 [nucleus] GO:0005654 [nucleoplasm] GO:0005737 [cytoplasm] GO:0005829 [cytosol] GO:0006351 [transcription, DNA-templated] GO:0006355 [regulation of transcription, DNA-templated] GO:0006367 [transcription initiation from RNA polymerase II promoter] GO:0006810 [transport] GO:0007165 [signal transduction] GO:0007264 [small GTPase mediated signal transduction] GO:0007267 [cell-cell signaling] GO:0007548 [sex differentiation] GO:0008013 [beta-catenin binding] GO:0008134 [transcription factor binding] GO:0008270 [zinc ion binding] GO:0008283 [cell proliferation] GO:0008284 [positive regulation of cell proliferation] GO:0008285 [negative regulation of cell proliferation] GO:0010467 [gene expression] GO:0010628 [positive regulation of gene expression] GO:0016049 [cell growth] GO:0019899 [enzyme binding] GO:0030521 [androgen receptor signaling pathway] GO:0030522 [intracellular receptor signaling pathway] GO:0030850 [prostate gland development] GO:0042327 [positive regulation of phosphorylation] GO:0043234 [protein complex] GO:0043401 [steroid hormone mediated signaling pathway] GO:0043565 [sequence-specific DNA binding] GO:0044212 [transcription regulatory region DNA binding] GO:0045597 [positive regulation of cell differentiation] GO:0045720 [negative regulation of integrin biosynthetic process] GO:0045726 [positive regulation of integrin biosynthetic process] GO:0045893 [positive regulation of transcription, DNA-templated] GO:0045944 [positive regulation of transcription from RNA polymerase II promoter] GO:0045945 [positive regulation of transcription from RNA polymerase III promoter] GO:0046983 [protein dimerization activity] GO:0051092 [positive regulation of NF-kappaB transcription factor activity] GO:0051117 [ATPase binding] GO:0051259 [protein oligomerization] GO:0090003 [regulation of establishment of protein localization to plasma membrane] GO:2001237 [negative regulation of extrinsic apoptotic signaling pathway]