We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
RNA tissue category: Group enriched (cerebral cortex, hippocampus, hypothalamus)
FANTOM5 dataset
Organ
Expression
Alphabetical
RNA tissue category: Group enriched (hippocampus, brain)
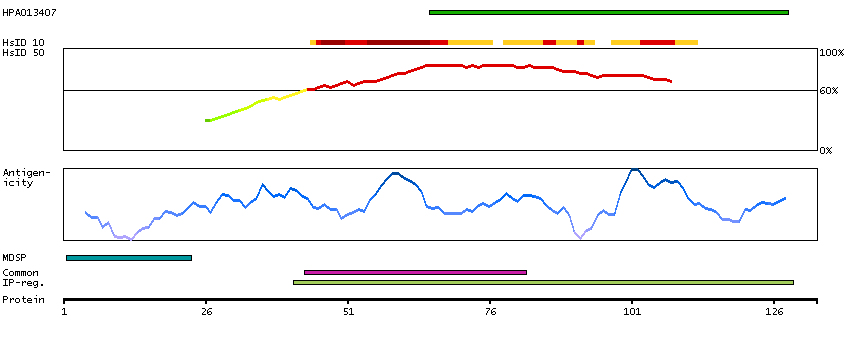
GENE INFORMATION
Gene name
FAM19A1 (HGNC Symbol)
Synonyms
TAFA-1
Description
Family with sequence similarity 19 (chemokine (C-C motif)-like), member A1 (HGNC Symbol)
Entrez gene summary
This gene is a member of the TAFA family which is composed of five highly homologous genes that encode small secreted proteins. These proteins contain conserved cysteine residues at fixed positions, and are distantly related to MIP-1alpha, a member of the CC-chemokine family. The TAFA proteins are predominantly expressed in specific regions of the brain, and are postulated to function as brain-specific chemokines or neurokines that act as regulators of immune and nervous cells. [provided by RefSeq, Jul 2008]