We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
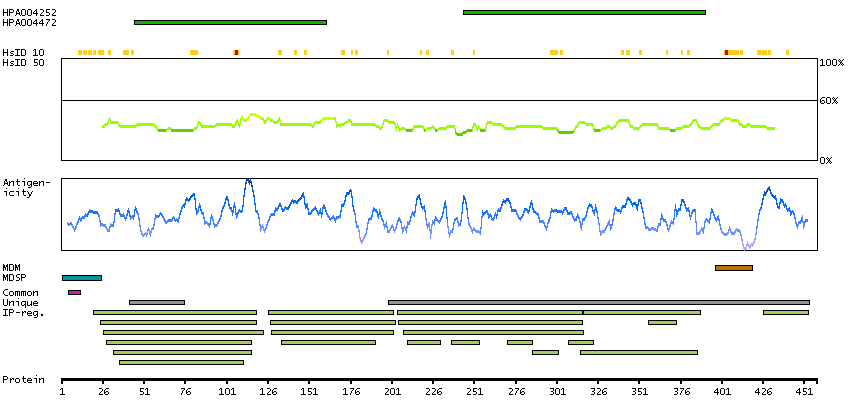
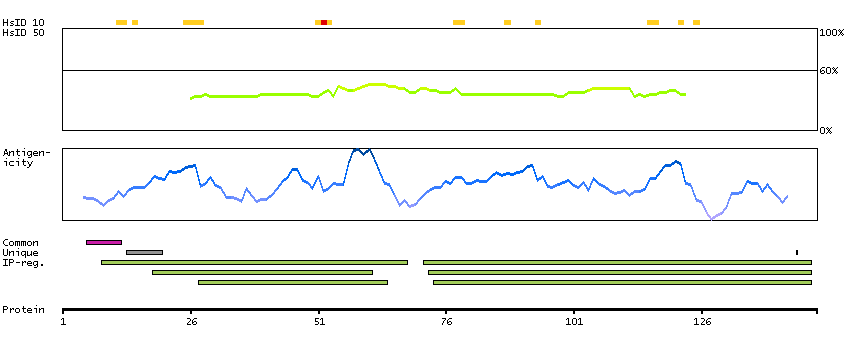
This gene encodes a membrane glycoprotein of T lymphocytes that interacts with major histocompatibility complex class II antigenes and is also a receptor for the human immunodeficiency virus. This gene is expressed not only in T lymphocytes, but also in B cells, macrophages, and granulocytes. It is also expressed in specific regions of the brain. The protein functions to initiate or augment the early phase of T-cell activation, and may function as an important mediator of indirect neuronal damage in infectious and immune-mediated diseases of the central nervous system. Multiple alternatively spliced transcript variants encoding different isoforms have been identified in this gene. [provided by RefSeq, Aug 2010]