We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
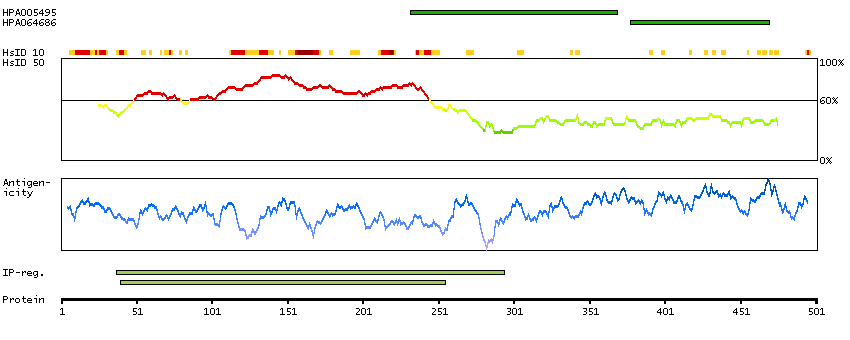
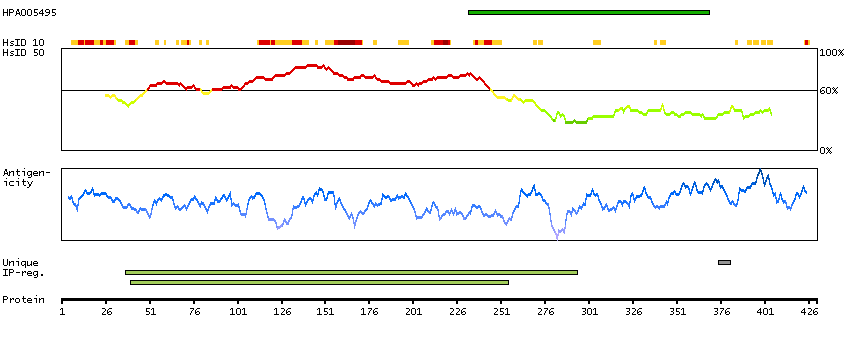
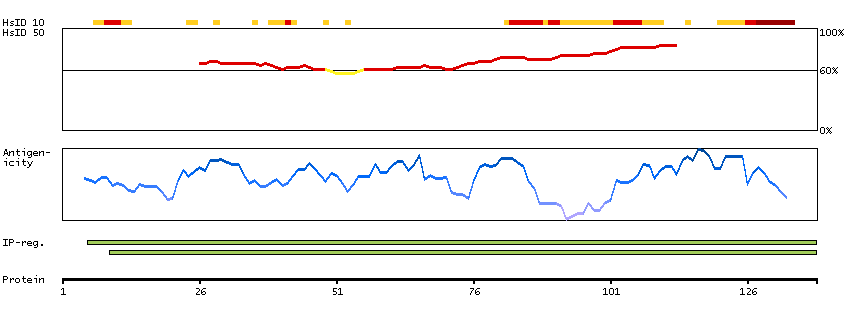
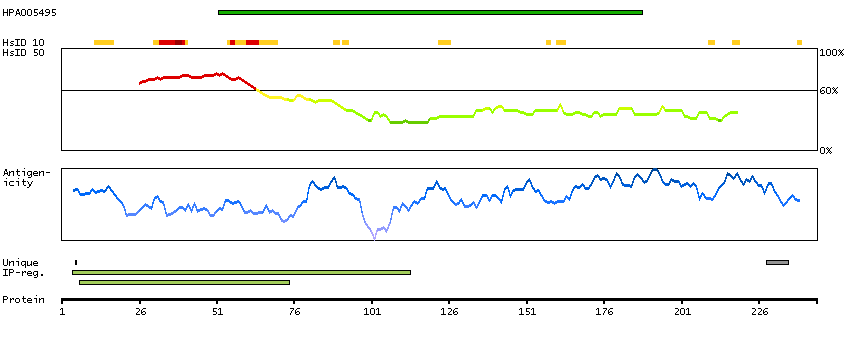
This gene encodes a member of the the glycogenin family. Glycogenin is a self-glucosylating protein involved in the initiation reactions of glycogen biosynthesis. A gene on chromosome 3 encodes the muscle glycogenin and this X-linked gene encodes the glycogenin mainly present in liver; both are involved in blood glucose homeostasis. This gene has a short version on chromosome Y, which is 3' truncated and can not make a functional protein. Multiple alternatively spliced transcript variants encoding different isoforms have been identified.[provided by RefSeq, May 2010]