We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Cases of hepatocellular carcinomas, endometrial, lung and urothelial cancers displayed moderate to strong immunoreactivity. Remaining malignant cells were generally negative.
A few liver tumors and endometrial cancers showed weak to moderate cytoplasmic staining. In some squamous cell cancers and urothelial cancers a fraction of the tumor cells were positive. Distinct positivity was observed in endothelial cells and tumor stroma. Remaining malignant cells were in general negative.
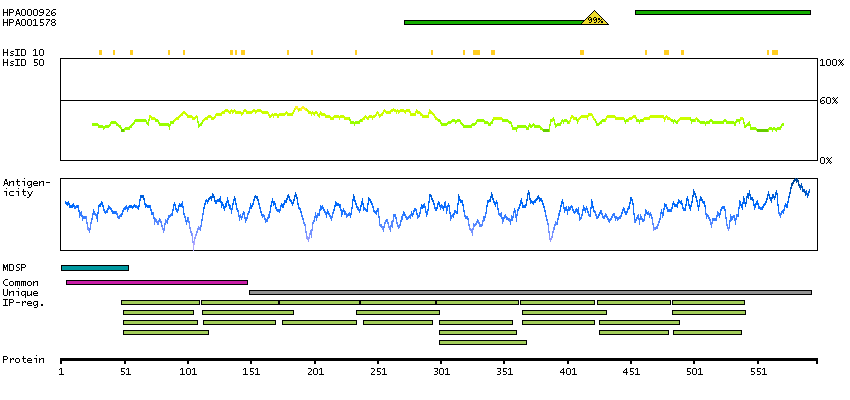
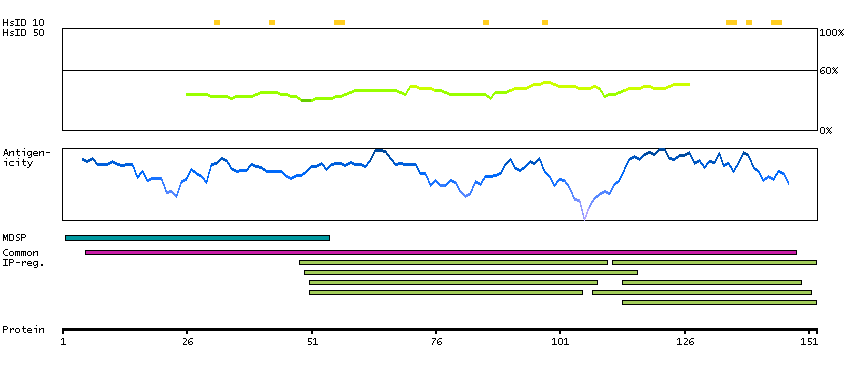
This gene encodes a member of a superfamily of proteins composed predominantly of tandemly arrayed short consensus repeats of approximately 60 amino acids. Along with a single, unique beta-chain, seven identical alpha-chains encoded by this gene assemble into the predominant isoform of C4b-binding protein, a multimeric protein that controls activation of the complement cascade through the classical pathway. The genes encoding both alpha and beta chains are located adjacent to each other on human chromosome 1 in the regulator of complement activation gene cluster. Two pseudogenes of this gene are also found in the cluster. [provided by RefSeq, Jul 2008]
P04003 [Direct mapping] C4b-binding protein alpha chain
Show all
MEMSAT3 predicted membrane proteins Predicted secreted proteins Secreted proteins predicted by MDSEC Phobius predicted secreted proteins SPOCTOPUS predicted secreted proteins Plasma proteins Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)