We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
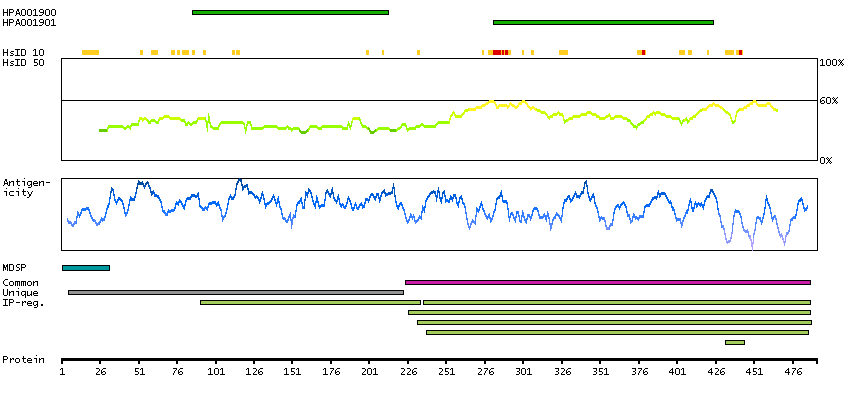
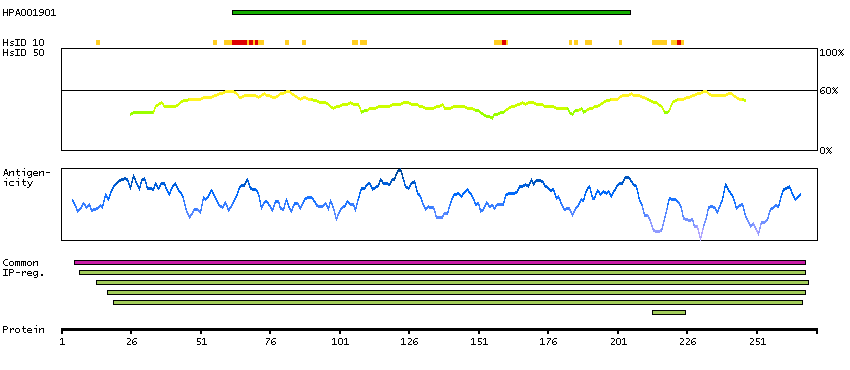
The protein encoded by this gene is the beta component of fibrinogen, a blood-borne glycoprotein comprised of three pairs of nonidentical polypeptide chains. Following vascular injury, fibrinogen is cleaved by thrombin to form fibrin which is the most abundant component of blood clots. In addition, various cleavage products of fibrinogen and fibrin regulate cell adhesion and spreading, display vasoconstrictor and chemotactic activities, and are mitogens for several cell types. Mutations in this gene lead to several disorders, including afibrinogenemia, dysfibrinogenemia, hypodysfibrinogenemia and thrombotic tendency. Alternatively spliced transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, Jun 2014]