We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
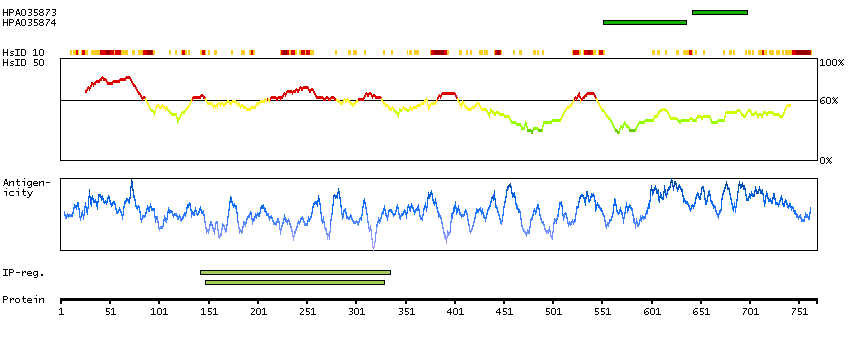
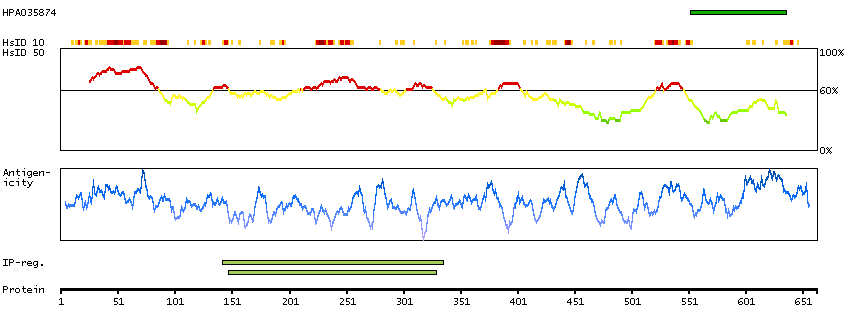
Adducins are a family of cytoskeleton proteins encoded by three genes (alpha, beta, gamma). Adducin is a heterodimeric protein that consists of related subunits, which are produced from distinct genes but share a similar structure. Alpha- and beta-adducin include a protease-resistant N-terminal region and a protease-sensitive, hydrophilic C-terminal region. Alpha- and gamma-adducins are ubiquitously expressed. In contrast, beta-adducin is expressed at high levels in brain and hematopoietic tissues. Adducin binds with high affinity to Ca(2+)/calmodulin and is a substrate for protein kinases A and C. Alternative splicing results in multiple variants encoding distinct isoforms; however, not all variants have been fully described. [provided by RefSeq, Jul 2008]